

Document capture technology has come a long way in its roughly 3 decades of commercial application. But, much of that
advancement has remained masked behind esoteric verbiage and abstruse pricing structures. Is there really anything new
going on with today’s systems? It can be hard to tell from an outside perspective.
But, one truly substantial development in recent years has been the rise of Intelligent Document Capture (IDR)
solutions. So, what exactly makes this technology different from what came before it? In this article we hope to
de-clutter the scene, and demonstrate how IDR dramatically streamlines the capture of even highly unstructured,
natural-language documents. We think lightweight modern systems that make use of IDR, such as Ephesoft, are creating huge
new opportunities for firms to capture their most important data. Today we’ll discuss how this works, and what it means
for your enterprise.
The Roots of Document Capture
In the early days of document capture technology, the only extraction method was Fixed Form processing.
This approach was based on defining simple capture boxes within documents or pages, and the system would scan these zones
for any content at all, and attempt to extract whatever was found. This approach was optimized for document types that were
highly regular, where data would show up in predictable, describable geometric locations. Similar technology was devised
for handling checkboxes, X’s, fill-in bubbles, and barcodes. This approach to capturing information defined the industry
for a number of years.
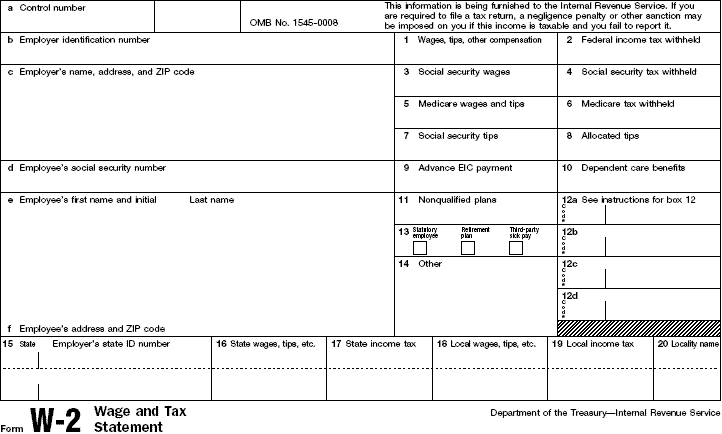
An example of the kind of document for which Fixed Form processing is ideal.
But, Fixed Form processing had serious limitations. The majority of organized business documents are not rigid,
but are semi-structured. For example, documents such as invoices, Explanations of Benefits, and so on; these kinds of
records have generally predictable content, but there isn’t any way to predict where on the page key pieces of data would
appear. For that reason, Fixed Form processing was never applicable to a huge portion of important business records. And
the situation was even more difficult for totally unstructured data, such as free-written letters and email.
How IDR Fills the Gap
For these less-structured document types, the subfield of intelligent document recognition was developed.
This new approach takes a content-based, rather than layout-based, approach to documents. Most modern capture solutions
that utilize IDR depend on a pre-production learning phase, during which human operators provide example documents.
The software then scans and analyzes all the words on every page in order to build a statistical model of word
relationships and probabilities. For example, an operator may provide an example of both a mortgage document and a
land usage document; the system will build a model that effectively notes the presence of terms like borrower,
SSN, interest, and principal in the former document, while prioritizing words such as
title, bounds, survey, easement, and so on for the latter. In actuality, this
example is quite simplistic, whereas the extensive matrices that today’s systems can generate are quite nuanced and
sophisticated.
Having created predictive models for these different types of documents, a modern capture system can then easily and
correctly recognize other instances of the same document – e.g. two title surveys from the same company. But, much more
usefully, it will also be able to correctly recognize and classify completely novel documents of the same type,
like a title survey from a different surveyor, which might have an entirely different layout, and a handful of different
terms too. How is this possible? Since IDR leverages probabilities rather than absolute relationships, it is flexible
enough to tolerate slight differences in data. That novel set of title surveys might have somewhat different verbiage,
but will likely retain > 90% of the same overall vocabulary because it is still a survey. This is the paradigm at the
heart of IDR – document recognition in today’s solutions is no longer a rote and mechanical process, but is actually
semantically-based, adaptable, and truly intelligent.

An IDR perspective on two documents from the same industry, but prepared by different firms — while they do not have
identical geometric layout or keyword terms, there is enough semantic data in common that these two would be easily
recognized as belonging to the same document class.
Today, state-of-the-art document capture solutions like Ephesoft leverage the power of IDR along with a mix of other
different data extraction methods. Training a system like Ephesoft to recognize your documents can require as little as
a couple of minutes, and this training and classification scheme can be modified on the fly whenever your needs or
documents change. So, while it may seem that your data is too unpredictable or impractical to be scanned and extracted by
automated systems, you might be surprised to see just how capable and agile today’s tools really are, and how valuable
the results can be for your enterprise.

