

We’ve written about why we love Ephesoft — it’s a powerful, efficient solution for intelligent document capture, with a disruptive pricing model.
Now with the recent release of version 3.1, Ephesoft is again demonstrating a superb level of attention to real-world client use cases, by rolling out some new features that really get us excited! Here we explore just a few enhancements to their Extraction module that promise to extend Ephesoft’s reach substantially, and reduce the workload required of administrators and developers.

Fuzzy Pattern Extraction
Ephesoft’s existing regex-based extraction rules can already incorporate a lot of flexibility and intelligence. But, at times when source images or are dirty, old, skewed, or low resolution, even the best-constructed regex search can get fouled up by lack of good OCR data. In that case, the standard fix is to add in in a variety of OR statements in an attempt to cover all possible [bad] renderings due to low quality source material. This gets to be a headache somewhat quickly.
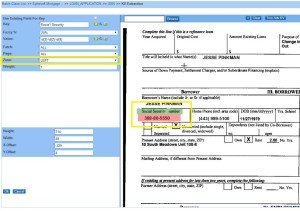
But no longer. Ephesoft 3.1 now includes a simple field — Fuzzy % — that allows your search pattern to easily accommodate a range of partial data matches. The screenshot at right demonstrates this with a regex search for “Social Security Number”. The document itself includes a smudge, which would likely produce a false negative in a conventional search — but the new Fuzzy % field easily accommodates this variance.
We can’t wait to use this, as it will save a lot of development time on extraction logic, especially when we find a high degree of variation in the source documents being scanned.
Zone-based Extraction
Extracting a simple document field such as Invoice Date is usually a cinch with Ephesoft. Regex- and position-based extraction rules enable rapid identification and parsing of such fields in most cases. But, what if your source documents have a number of similar-looking Date-like fields, all throughout the document? Maybe your document includes a couple of columns or rows, or 2+ forms per page, and thus contains several identical instances of this same field? Up to this point, there wasn’t an easy way to distinguish between these similar hits in the document, which in reality correspond to several distinct metadata points.
Now, we have a new field — Zone — that allows an operator to constrain any extraction rule to a particular area of the page. Just as in the case of the example, above, this simple addition is going to be a big pressure relief for building lightweight, efficient extraction logic for a particular document set. What used to be a puzzling extraction puzzle now is made simple and straightforward, by simply constraining the search to a spatial area of each page.

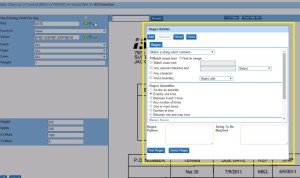
Regex Builder
For those veteran data workers who have no trouble whipping up a regex pattern, building out extraction logic in Ephesoft is no great challenge. But what about those who aren’t quite so seasoned with regular expressions? Ephesoft 3.1 now includes an integrated Regex Builder, which can be leveraged on any extraction field throughout the entire application.
This opens up extraction development and QA work to a much broader audience. From what we’ve seen, the Regex Builder is a well-built tool that will allow regex novices to construct a wide range of capable, and more importantly readable search patterns, without any great headaches. We may not necessarily be the target audience for this feature, but we know that having the Regex Builder on board will allow our clients to exercise more independence and confidence with Ephesoft’s extraction logic, so that’s a big win for everyone.
Conclusion
Altogether, we are excited to sink our teeth into Ephesoft 3.1. What we’ve seen so far demonstrates that Ephesoft has focused their engineering on key additions that will really impact the user experience and workload that comes with their platform. Kudos to the upgrade! We’ll add more to this list at a later time as we get our feet wet.


{kind=link}
{kind=link}