

In part one we explored some strategies to address variability in the appearance of data within documents that might be
captured by Ephesoft in document-level fields. But what if we’re trying to capture whole tables of data that might exhibit
the same variability?
This may again seem to be a daunting challenge, but Ephesoft has a number of options within its tabular extraction suite
that can be utilized to accommodate even an inconsistent data set. Below we’ll look into how to leverage these options
and achieve the best automated extraction possible with a set of documents that may not be ideally uniform.
For detail on how the overall table extraction area works, there’s a great tutorial video at
EphesoftUniversity – the steps below will assume basic familiarity with these concepts.
Step 1: Understand how Ephesoft is able to locate tabular data
Ephesoft has three available methods by which tables within documents can be identified and extracted:
- Column coordinates:
If tables show up at a reliable visual position within our documents, we can just use straightforward geometric coordinates to predict where tabular extraction logic should begin on a page. - Column Headers:
If our table columns have headings at the top that are unique enough to distinguish them from the rest of the content on the page, we can use those header name patterns to signal Ephesoft to begin tabular extraction where they occur. - Regex Validation:
If the actual data within our tables is appreciably unique and different from the rest of the content on the page, then we can use regex pattern matching alone to flag those data as candidates for tabular extraction.
Not only can we make use of any of these methods, but Ephesoft can combine these methods using Boolean AND/OR statements
in order to build the most flexible and confident table extraction model possible. Note the Boolean operators available
here on the Table Listing setup screen:

An empty Table Info Listing within Ephesoft, showing the available extraction methods.
So, in terms of hunting down the tabular data within our document set, Ephesoft has supplied us with a versatile arsenal
of methods here.
Step 2: Determine which methods can be used
In this article we’ll continue with the original data set we used, shown here.

The original set of four sample documents from Part 1.
These few documents are all surveys of the same type and nature, but they exhibit some variation amongst themselves.
Here we’ll consider the variation and look at what that means for the methods we can use:
- The documents show an inconsistent layout and position of the tabular data, so we cannot use Column Coordinates as an extraction method.
- The documents have somewhat consistent headings at the top of each table, so we probably can use Column Header as an extraction method, at least for some of the data.
- The actual data in the tables is all numeric and limited in terms of number of digits, etc. While this alone might not be enough of a pattern to differentiate the data from the rest of what’s on each page, it will certainly help. So we definitely can use Regex Validation as an extraction method.
So, there we have it. With our methods selected, we can proceed with the detail work.
Step 3: Build regular expressions
Now the majority of the work comes down to authoring regex statements that succeed in capturing the best possible
portion of our data. In cases like these, this can be a balancing act, and requires trial and error. We need to allow
enough tolerance into our regular expressions such that small variations in OCR rendering will be allowed as matches,
but at the same time avoid capturing a flood of false positive data.
Here we’ll sketch out the general progression of trial-and-error that eventually will get us to a well-rounded set of
regex statements:
- Start with a single field or goal. In this case we’ll work exclusively on a column header called Inclination, which shows up similarly in each of our four documents.
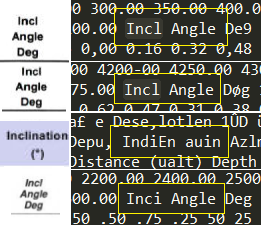
- Just as in Part 1 of this tutorial, we take note of the various ways that Inclination shows up both visually and in the rendered XML data. For our four documents, these instances are pictured below, with visual screenshots paired with their OCR renderings. As always, what the XML shows is substantially dependent on the original scan quality of each image.

Four different versions of the “Inclination” column header, and how they show up in the rendered XML data.
- We always want to start the authoring process with a simple regex pattern that matches the majority of the data. In this case it might just be Inc. From there we hit the Test button and see what results.
- We address each missed match as a separate case — drilling into the XML for that particular document, seeing what the data is doing, and very carefully tweaking our working regex pattern to attempt to accommodate the variations in the data.
- We test again, and note both any new positive matches, and any new false positives. Steps need to be taken to increase the former and eliminate the latter. It helps here to keep careful notes of our regex statement at different stages of development. Test again!
Eventually we’ll arrive at a regex for this particular field that accommodates the whole data set as much as possible.
Just as at the end of the Part 1 post, we’ll need to make decisions regarding problematic documents – do we try to re-scan
them, adjust regex to accommodate them, or throw those documents out for manual entry? These decisions will have to made
on a piecewise basis.
In this case we’d need to repeat this process for each Column Header that we wanted to capture. Since our actual table
data is numeric, building the regex for the Column Pattern fields will likely be more straightforward. Similarly, whatever
goes into our Column Pattern fields can be reused in the corresponding Between Left and Between Right fields.
At the end of all this, we’ll have a working table extraction model that should accommodate new documents of similar
character. Hopefully this tutorial series has provided a clear set of ideas and best practices, in order to get started
with extraction logic on more challenging and variable document sets. Good luck! Feel free to let us know how these methods
work for you in the comments section below.

