
If you’re reading this article on the ArgonDigital website, you might not realize that what you are reading is actually a blog entry. Unlike the rest of the Blue Fish website, our articles, interviews, and presentations are created using EMC Documentum Web Publisher 5.3, but published as entries in a WordPress blog!
By treating our articles as blog entries, Blue Fish authors can receive direct feedback from readers via comments and ratings. Additionally, integrating a blog with the Blue Fish website enhances Search Engine Optimization – Google and other search engines favor sites with frequent updates and numerous links to and from other websites.
Rather than build our own blogging solution, Blue Fish decided to use WordPress. WordPress is free, simple to use, and an entire community of existing users and developers are available for support and enhancements. Thousands of free plugins are available for WordPress to track usage, enable PHP functionality, and enhance the end user experience which saved us valuable development time.
Integration Goals and Benefits
The main goal of our integration between Web Publisher and WordPress was to allow a content author to create content in Web Publisher, publish the entry, and have that content be automatically loaded into WordPress. The author shouldn’t have to use WordPress’ administrative tools when publishing articles.
Another (trickier) goal was to automatically update the entry in WordPress whenever the article content in Web Publsher is updated.
Our final goal was to be able to control which types of content get published to WordPress. At Blue Fish, only our articles, presentations, and interviews are published into WordPress. Press releases, team member bios, product descriptions, the home page, and other types of content have no connection to WordPress – they are published as static web pages using traditional Web Publisher methods. Because only some of the content in Web Publisher is pushed to WordPress, we needed our integration solution – and not our content authors – to handle this differentiation automatically.
A seamless integration between WordPress and Web Publisher gives us the following benefits
- Our content authors only have to learn one authoring system – Web Publisher – while getting the benefits of comments and ratings that WordPress provides.
- We can enforce consistent HTML for both traditional content and blog entries by using XSL stylesheets in Web Publisher.
- It’s easy to make visual design changes to both traditional content and blog entries by reapplying XSL stylesheets in Web Publisher.
- We can maintain uniformity across multiple content authors by using templated authoring for both traditional content and blog entries.
- All the archiving and security benefits of a Content Management System are available for our WordPress content (articles, presentations, and interviews).
The integration between Web Publisher and WordPress can be divided into the three steps illustrated in Figure 1.
- The first step is the creation, modification, and publication of content in Web Publisher. This is performed manually by our authors just as it is in standard Web Publisher environments.
- The second step is a custom java application that gets called as part of Web Publisher’s content publishing process. This java application is the real meat of the integration and is responsible for sending the content from Web Publisher to WordPress.
- The third step is the consumption of the second step’s output by WordPress. We had to modify WordPress a little bit in order to support updating existing articles, but mostly this is out-of-the-box WordPress functionality.

Figure 1:
High Level Integration Process Flow
Integration Implementation Design
Web Publisher (Content Creation, Modification, and Publication)
A Blue Fish content author creates or modifies a piece of content in Web Publisher using a predefined template. Even though the content will ultimately be published to WordPress, the user experience is the same as creating traditional website content because these steps use standard Documentum functionality.
The diagram below outlines what happens in Web Publisher when creating Articles and other content that will later be published to WordPress.
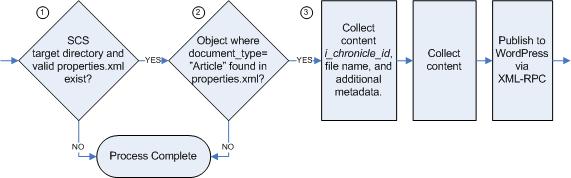
Figure 2
- Content is created via the standard template-based authoring in Web Publisher. In order for our integration to identify which pieces of content need to be published into WordPress, we set a custom attribute (document_type) on our Article template within Web Publisher. Our integration code only operates on content whose document_type attribute is set to “Article”.
- Web Publisher uses its XSL presentation file to create an HTML fragment from the content. The HTML fragment is then published to a temporary location via Site Caching Services (SCS).
- SCS calls a custom Java program that will load the content into Web Publisher (see the Custom Java Application section).
Configuring Site Caching Services to call a custom Java program
Documentum’s Site Caching Services (SCS) provides the ability to execute “Post-Sync Scripts” that perform additional actions after the content is published. Once configured, these scripts are executed after the publication of individual content pieces, after the dm_WebPublish job runs, and after a Site Configuration is published from EMC Documentum Administrator.
The post-sync script is configured using EMC Documentum Administrator (Figure 3).
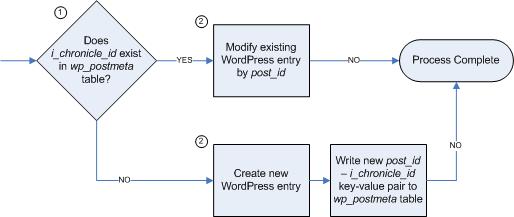
Figure 3:
Post-Synch Configuration in Documentum Administrator
The post-sync script must be a command line executable file such as a .bat, .sh, or .exe file. Blue Fish uses a batch file called sendToWordPress.bat to execute a Java program. The script is placed in the %scs_install_directory%productbin directory.
Tip
The post-sync script configuration can also be defined in Site Caching Service’s agent.ini file.
If this is the case, the script can be placed in a subdirectory of
%scs_install_directory%productbin
with an explicit location configured in the agent.ini file.
SCS passes eight arguments to the script. The second argument is the location of the properties.xml – the file used to transfer attribute metadata from the repository to the target host. The properties.xml file contains all the metadata for the files being published, including our custom attribute, document_type. Blue Fish passes the location of properties.xml as an argument to the custom Java application which in turn parses the XML file to determine which of the published files are articles that need to be loaded into WordPress.
Further information on SCS post-sync scripts, including all eight arguments and sample scripts, can be found in Documentum’s Site Caching Services User Guide.
Custom Java Application (Post-Sync Script Execution)
The execution of the post-sync script and the resulting call to Blue Fish’s custom Java class is how published content from Web Publisher gets added as WordPress blog entries.
Our custom Java class’ execution path is illustrated in Figure 4 and explained below.
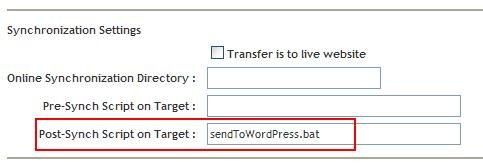
Figure 4:
Custom Java Class Execution Path
- First, we check that the properties.xml exists and that it is valid XML. This file should exist at the location specified in the second post-sync script argument.Tip
If the properties.xml does not exist, check that SCS is properly configured to publish metadata using EMC Documentum Administrator and by following the directions supplied by EMC Documentum.
- Parse the properties.xml and check for the existence of one or more entries with the proper custom attribute value (document_type equal to Article). If no new entries exist in this publication, the following steps are skipped and the publishing is complete.For each entry’s XML node in the properties.xml, there will be entries for the content’s i_chronicle_id, file name, and additional published metadata such as the article author’s name and article title. Each one of these XML nodes is a future blog entry, and there are just a few more steps to get them from SCS to WordPress!
- For each future blog entry, the filename from the properties.xml is used to open and read the physical published content. These published HTML fragments are used moments later to create the blog entry’s body and excerpt.
WordPress (Parsing and consuming blog entries)
WordPress supports a number of integration points that allow external applications to communicate with it. We chose to use the Blogger API due to its simplicity and the quality of the available documentation. (The Blogger API has since been deprecated, but is still included with WordPress. Other APIs, including the Atom API, are also supported by WordPress.)
The Blogger API allows external programs to create and modify blog postings, which is almost exactly what we need. However, because WordPress stores blog entries with post_id as the unique ID and Web Publisher uses i_chronicle_id to identify unique pieces of content, some modification and extension of WordPress is necessary to map WordPress’ post_id to Documentum’s i_chronicle_id.
Our implementation stores the i_chronicle_id in a “extended property” in WordPress using the wp_postmeta table. The wp_postmeta table is a WordPress feature designed to be used for the extension of content properties, and by storing an article’s i_chronicle_id in this table, we can map a WordPress post to its corresponding Documentum content file.
By modifying the Blogger API to accept i_chronicle_id as an argument, our integration can locate an existing article and update it when necessary.
This enhancement was made in the WordPress xmlrpc.php file to the appropriate Blogger API methods. Our integration strategy included changes to the Blogger.newPost method to read the i_chronicle_id and if no existing record exists in the wp_postmeta table for this entry, create the new blog entry while storing the i_chronicle_id–post_id key-value pair. If an entry in the wp_postmeta table already exists, the method modifies the existing blog entry appropriately.

Figure 5:
Consumption of blog entries by WordPress
Our WordPress code is initiated when our custom Java Program (see previous section) makes a call to our modified Blogger API. The HTML fragments that are destined to be blog entries, as well as the article’s i_chronicle_id and additional metadata, are transmitted via XML-RPC to WordPress.
- Our modifications to WordPress check if the i_chronicle_id for the blog entry exists in the wp_postmeta table. The inclusion of the i_chronicle_id is the final integration point that links content created in Web Publisher with WordPress’ underlying database.
- The modifications made to WordPress ensure that if a row in the wp_postmeta table already exists for a given i_chronicle_id, the proper blog entry is loaded and modified.
- If no such wp_postmeta entry exists, a new WordPress post is created and the key-value pair is stored in the wp_postmeta table.
Closing Thoughts and Considerations
Integrating Web Publisher and WordPress is a relatively straight forward technical problem that can add huge business value to WCM solutions. Opening two way-web communication channels between our authors and our readers is an exciting new way to increase interest in what we do.
Instead of spending valuable time replicating functionality in existing blog packages, integrating EMC Documentum Web Publisher with WordPress quickly brings comments, ratings, and more to our website. Future design changes to our website can be applied directly to existing blog entries using Web Publisher to create a seamless end user experience. Most importantly, a technical integration, as described in this article, allows our authors to spend time creating exciting new content – not tweaking HTML to blend the blog into our website.


