

Leveraging Automated Data Extraction in the Oil & Gas Industry
As a preface to this article, our own Lisa Hill (VP of Technology Strategy), Gary Cox (an ArgonDigital Technical Architect), and guest Dan Champ from Ephesoft presented a webinar discussing the power of Ephesoft automated data extraction using oil & gas engineering documentation as a real-world example.
Now, let’s go over some of the key features and insights that they shared…
Data Extraction Terminology
We’ll start with a few basic definitions to establish a common vocabulary.
- Capture – the end-to-end process of acquiring a document, analyzing the documents, and then releasing the relevant information to feed business processes
- Batch – a set of one or more document(s) that are being processed as a group
- Batch Class – the set of business rules that are being run against a Batch
- Image Processing – the act of page separation, image normalization and cleanup, and whole page analysis
- Classification – the act of deciding what type of document is being analyzed (this gives context to how you are looking at the page)
- Metadata Extraction – the act of pulling salient information / data out of documents (for example, pulling the amount due off of an invoice)
- Validation – human review of classification and/or extraction results
- Delivery – export document and data to the appropriate business systems
Automated Data Extraction with Ephesoft Transact
Ephesoft Transact is an intelligent data capture and data enrichment solution that extracts meaningful data from any document. A lot of our clients use or implement Ephesoft because it’s a powerful and flexible document tool. We’ll walk through some of its key features as though we were processing a real set of documents.
The Business User Experience
From a business user point of view, some of the most important capabilities are being able to view and review documents and their extracted data.
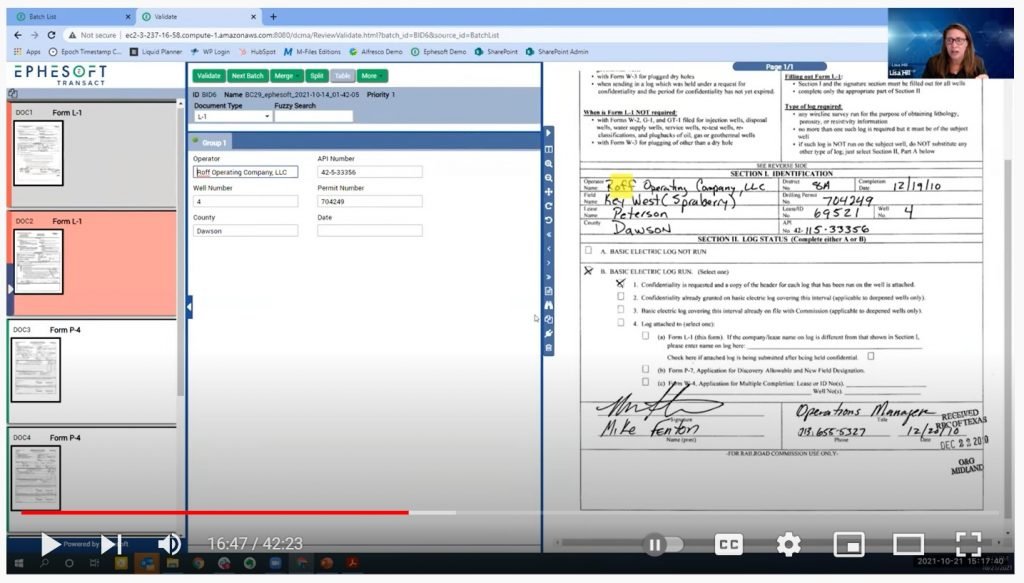
View my documents shows us the batches of documents that are currently being processed and are in need of human review to validate the classification and/or extraction results. In our oil and gas example, we are looking at batches that include things like directional surveys, log files and even plats. We can also see the confidence level assigned to each automated action, and documents that have results with lower confidence levels are highlighted to draw my attention to them.
On the same page, in the middle pane, we can see the metadata that has been automatically extracted. The metadata that is flagged as low confidence is highlighted red to attract my attention. Conveniently, I can update any metadata directly in this pane instead of having to navigate to a different page.
From here we can also view the tabular data from the document. We simply click on the tabular view to see a table with the data extracted from all the pages of this document.
What’s really powerful is the Cloud Hyperextender technology that allows us to process and pull data from handwritten documents as well. Until recently, using AI to process handwritten documents really didn’t work, but now even “messy” handwriting can be understood and processed by the system, and it saves a TON time!
Ephesoft Set Up and Administration
From a system administrator point of view, Ephesoft has some really powerful tools that let us set all of this up so that this document processing works seamlessly for the end user.
Something that every organization is concerned about is document security. To maintain data integrity, you don’t need the accountants in the plat maps and the engineers in the invoices. Ephesoft allows you to set up not only specific roles but also restrictions by document batch class so that you can protect your documents and simplify the user experience.
Ephesoft Transact’s AI comes with some built in “pre-training”, but you’ll want to teach it the unique documents, document properties, and rules that your organization requires. The good news is, you’re in charge of the machine learning process. The better news is, you don’t have to be a code-slinger to do this!
Training the Document Classification AI
There are several ways you can train Ephesoft Transact to classify and process your documents, and below we’ll cover some of the main techniques.
Search Classification is the most commonly used classification method. To set it up, bring in blank samples of first, middle, and last pages of the documents you use. It’s critical for the document separation logic to have first and last pages understood by the AI.
Once you’ve done this, you can start running documents and they should be classified by type. You’ll want to verify that it’s working as expected, and luckily there’s a built-in test tool that lets you do that using sample documents.
Other classification techniques you might use are image, key value, and bar code classifications.
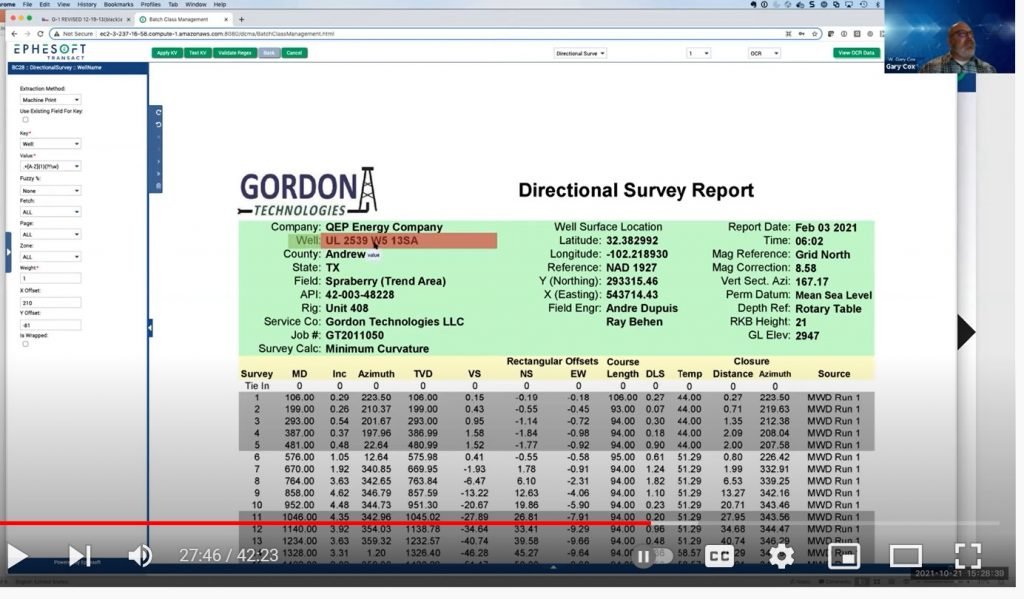
Training the Data Extraction AI
The next step in the machine learning process is data extraction from the classified documents. The tools to do this include index fields with rules for each field and key value extraction using an anchor target to find the key and related value. On the sample document you can point to the location of the index field and where in relation to that the value is. It uses pattern matching for both the key and value. You can also tell it what page (or all pages) it should look for that data on. And you can have more than one rule and weight the rules for a single field. In short, you teach the system just the same way you would teach a human!
As you develop the rules, you can test them on the fly with the test tool.
Some flavors of automated data extraction logic that you might set up include:
Paragraph Extraction – you teach the system to look for the values that match the pattern you’ve established between the start and end point of a paragraph text.
Table Extraction – choose what tool you want to extract tabular data from a document. We usually use column, header, and regular expression extractions.
Automated Validation – for fields where you need precision you can set up automated validation rules to determine whether the extracted data meets the expected pattern. Essentially a “double check”, no human required.
Normalization Logic – the classic use case is in dates – we all know that the same date can be represented in a huge variety of formats (2/1/22, 02/01/2022, Feb 1 2022, etc.). The system can convert this information into the single format that our downstream systems require. This same sort of normalization can be preformed against any type of data that requires it.
If you’d like to learn more about how the power of automation and Ephesoft Transact can help your organization, give us a shout. We’re always happy to talk about our favorite topic – using technology to help you grow your business!

