

This is the fifth post in a series I am writing to discuss lessons I have learned about Data Migration. A 3-part discussion of Knowing Your Data can be found here. The first post on ETL is here.
We at ArgonDigital are always happy to discuss data migration with you and explore ideas about making your project go smoothly.
This week, I want to continue discussing Extract, Transform, and Load (ETL).
- Extract is about getting data out of the legacy system.
- Transform is about preparing it for the new system: mapping, breaking up or joining together source records, cleansing errant data, otherwise munging Source data into the structures and formats required by the Target system.
- Load is about putting it into the new system.
In my previous post, I posited that ETL is not a process in and of itself, but rather a set of activities which will need to be organized into a process design that is specific to your project. I discussed the Extract activity, and how the conditions and assumptions of legacy system data extraction varied widely across the three example projects to help customers replace legacy systems. These systems are a digital rights system, a financial system, and an asset management system.
Transform Activities in the ETL Pattern
As the name suggests, Transform is the set of activities your team will need to do to prepare your extracted data for loading into the target system. Transformation at the low end may include “cleansing” of extracted data: correcting misspellings, mapping old to new data types, and implementing taxonomies. More demanding transformation may involve pulling records from several systems in order to construct an entirely new schema for the business data object. At the high end, company staff may need to parse data from document or other non-system storage into rows and columns to be loaded into the target system. Transformation during migration is distinct from ongoing processing needs when exchanging data between production systems.
The general pattern of Transform activities is to design the to-be-loaded data structure (the tables, fields, and specific records you will put into the target system), create manual or scripted processes to reorganize extracted data, create standards and processes for cleansing data, and manage the transformation work to meet date and quality goals in readiness for migration. How you will do each of these will depend on many factors, which you can assess by answering these questions:
- How differently is data stored in the target system relative to the legacy system?
- Where will you store transformed data in the interim?
- How often (if ever) does source data change, and is it necessary to keep transformed data updated during the interim?
- What volume of data across business data objects (BDOs) is to be migrated?
- How much lead time does the team have for extraction activity?
Each of the three large migration efforts I have worked on has had distinct flavor in its transformation activity.

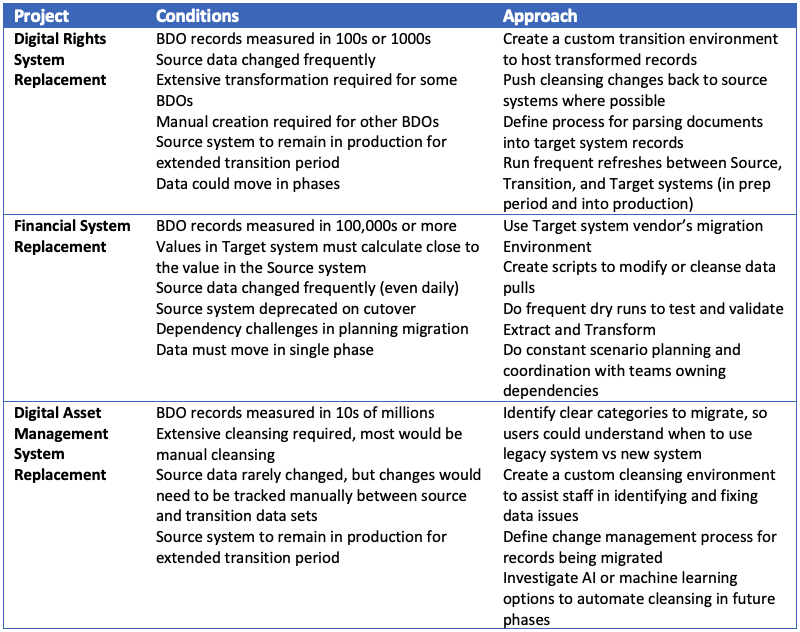
Project 1: Digital Rights System
A large media company was replacing its home-grown digital rights systems with a new SaaS built and maintained by a vendor. The team designed Transform activities according to key facts on the ground such as:
- The schema for one key Business Data Object (BDO) would need to be constructed from data extracted from at least four source systems.
- The data for another BDO did not exist in any source system. A massive effort would be required to parse field data from PDF documents into spreadsheet templates, which would then be uploaded into an intermediate environment for script-based transformation into the target schema.
- Different divisions kept different data about customers and partners (based on their distinct interactions with those companies). These data would be consolidated in the target system.
- Source data for many of the business data objects changed frequently, so that it was essential to push much of the cleansing back to the legacy systems.
Project 2: Financial System
A large financial services company was replacing its obsolete lease accounting system with a new on-premises system built and maintained by a vendor. The team designed Transform activities according to very different facts on the ground:
- The source system would need to be deprecated immediately upon migration. The business would cut over to the target system at that time and all records for all in-scope Business Data Objects (BDOs) would be managed on the new system as of the cutover.
- Migrated data would be used in financial calculations that would need to be accurate within tight tolerances compared to the old system’s calculations.
- Source data would require some cleansing, but considerable transformation since the source and target systems stored similar data points very differently. For example, the source system made liberal use of 2-digital symbols to represent attribute values (e.g., contract’s type) which would need to be mapped to the new system’s use of relational database conventions.
- Other systems that would feed data to the target system were being upgraded on different timelines, and each project’s schedule was changing. This made it difficult for the migration team to set solid expectations for those dependencies and required the transformation plan to account for several scenarios.
- And, of course, much of the source data changed frequently.
Project 3: Digital Asset Management System
A media company was replacing its in-house digital asset management system with a new cloud-based system built and maintained by a vendor. The dominant theme as the team designed Transform activities was the massive volume of digital assets:
- Millions of assets would need to be moved from the source system to the target. The source system would need to remain in production alongside the new target system for the extended transition period required to migrate millions of assets. The main challenge would be ensuring users knew on which system to find or edit a specific asset.
- Each asset had an associated metadata record, with dozens of user-entered fields. The source system did not help much in governing metadata, which meant manual cleansing would be required for many of the fields.
- Fortunately, source data was changed infrequently. However, it was cost-prohibitive to push cleansed data back to the source system, so the team would need a manual process to maintain cleansed and source data in synch prior to loading to the target system.
- There were system-managed fields in the source as well, which would need to be transformed in an intermediate environment, which would have to be carefully managed on upload in order.
Project Conditions Drive Approach
The conditions under which each team needed to plan the Transform and overall ETL drove very different approaches to the migration process. The table below summarizes conditions and implications on extraction process:
We’ll pick up the story again in the next post, on ETL & Load.

