

This is the third post in a series I am writing to explore lessons I have learned about Data Migration. You can read my first post, which describes steps 1.0 and 2.0 of the process to “Know Your Data” here. Read my second post which describes step 3.0 (field mapping) here.
We introduced our high-level process flow to illustrate how we have seen successful teams approach “knowing their data.” I will tackle Steps 4.0 through 6.0 in this post. Again, the process flow looks like this:

I’ll discuss steps 4.0 to 6.0 with stories about the challenges I’ve observed and the approaches these teams have taken.
Step 4.0 - Identify Linking Strategy
Our Business Data Diagrams (BDD) show relationships between data objects in an easy to grasp visual. The systems to be deployed for future state will establish links in their schemas or interlocks. Relational databases are built for this purpose: they can store unique identifier in the record for one data object and have access to the entire related Business Data Object’s (BDO) record. Replacing those unique IDs in the process of data migration is the next challenge in the Know Your Data process.
Imagine you have 3 BDOs called Contract, Project, and Partner, and the schema looks like this:
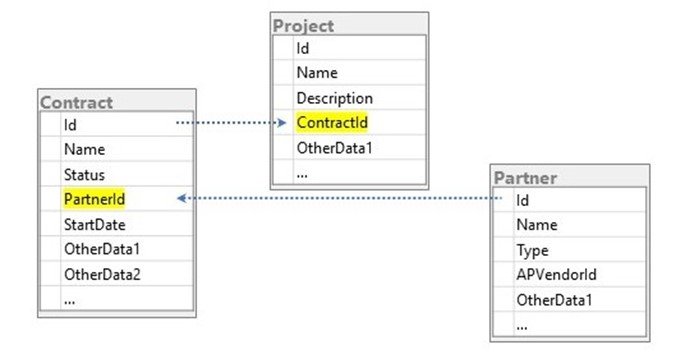
The different BDOs are linked in the legacy system and will also need to be link in the new target system. The challenge is that as part of migrating the Contract object, you will need to insert new values in the PartnerId field for each contract. As part of migrating the Project object, you will need to insert new values in the ContractId field for each project.
The most successful example I’ve seen involved a deployment to a new target contract system. The objects were a bit different: Products (rather than projects), Partners, and Contracts. The team constructed an intermediate system between the source systems and the target system. The intermediate system would:
- Store raw data pulled from source systems
- Provide simple UI to allow users to cleanse raw data – cleansed data would be stored in separate tables
- Allow for bulk data transformation where fields required it (example)
- Load data when cleansed to the target system (minus those linking IDs)
- Pull data back from the target system, to get the new IDs for each BDO record
- Facilitate bulk updates of old link IDs to the new system IDs
- Update the new target system’s records with the target system linking IDs
The team’s brilliant insight was that they could automate linking in this way, by pushing some data up to the target system so that it would create, say, a Product record. Then, they would immediately query that system to get the unique ID the target system had created for the record. The intermediate system required a large investment in dedicated team and tech, but allowed for an incredibly robust, fault-tolerant migration.
Step 5 - Confirm Scope
As noted above, data migration complexity will be a huge variable in most replacement projects. The ability to predict, plan for, and adhere to a target deployment date will depend on your ability to manage the scope of the data migration effort.
In one project, data scope was fixed as a project assumption. The project involved replacing a transactional system. Deploying the target system meant cutting over from the legacy system to the target system. As of the cut-over date, all transaction processing on the old system would stop and every transaction past that date would be processed on the new system. This meant that all data to be maintained and updated would need to be moved. The only way to control scope and risk, then, involved controlling the scope of capability/functionality enabled in the new system.
Another project involved exactly the opposite assumptions: functionality scope was fixed, but the amount of data could vary. The system involved was an asset management system which could eventually replace the legacy system, but the organization could migrate assets over time from highest priority to lowest. The team set a very conservative initial migration scope and committed to accelerating over time. They needed experience in measuring the effort, time, and people required to convert one unit of asset data. They needed to establish an initial process and plan for process improvement time to handle more data at a time in subsequent migration phases.

Step 6 - Create Validation Plan
Even if we do all the foregoing activities flawlessly, we cannot assume that data migration will yield complete and accurate data in the target system. In fact, the phrase “do the activities flawlessly” is an assumption. As with all things in our business, we must validate all assumptions and work.
Although my process flow shows a distinct step, 6.0 Create Migration Validation Plan, validation planning should begin as part of the earlier mapping steps.
- You will need to plan validation at the field, record, data object, and portfolio levels.
- At the field level, identify the method of confirming calculated fields match the intended values. Note that this may not be the same value as in the source system. In the financial system migration, the team had to accept that their target financial system worked differently than the source system. The validation exercise in that case was to predict the difference between the values in source and target, and to define an acceptable variance. If the actual migrated difference fell within the acceptable zone, the migration would be judged valid. (This difference would be tracked at the CFO level to ensure maximum transparency to internal and external stakeholders.)
- For each transformed field, identify the method of confirming the target field is assigned the appropriate value per your transformation rules. In the asset system migration, the team would have to do a random sample analysis to confirm that the migration scripts and processes assigned correct location entries per the taxonomy.
- For each business data object, identify the methods you’ll use to confirm at the record level that records being migrated are appearing as expected in the transition environment, and in the target system. For the contract system example, this meant validating that correct product attributes from the 7 different source systems were aligned into the given product record.
- At the data object level, identify the method to confirm that each data object is linked with the correct related objects. In the asset system migration, the team would have to generate reporting from source and target systems and use gap analysis to confirm that each partner or project had the same number of assets in each system.
- At the portfolio level, the entire set of data to be migrated and/or the set of data in the target net of the planned migration should also be validated. For the financial system migration example, validation at the portfolio level included measuring the total values of all contracts: assets, accounts receivable, yields, etc. For the asset system example, this included measuring the total number of asset records, the totals by partner, the totals by project, etc.
Thus, the validation planning must be a component of each migration workstream. There is distinct planning to do in step 6.0, with a focus on overall execution of the migration. Here are some thoughts, based on four years of recent migration work:
- Migrating data from a transactional system such as an inventory or accounting system is fundamentally different from migrating data from a non-transactional system such as a product catalog. In the financial system case, the migration:
- involved deprecating the source system immediately on migration.
- had to be executed at fiscal calendar month-end to facilitate financial reporting.
- had to be completed within a set period of time to avoid business disruption.
- The team running that migration did ongoing work to predict performance of the migration process and did frequent check-ins with the system vendor to solve for anticipated performance bottlenecks.
- The team planned several migration dry run events throughout the project, and even did a full “mock migration” event that included simulated validation of the migration. The experience from these events not only delivered needed process improvement, but also gave program leadership the confidence to execute the migration on schedule.
- In general, migration teams should follow the cadence of the overall project team. In the contract system migration case, the overall team used Agile methodology. So, the migration team built a project backlog with epics and stories. The Product Owner was fantastic; she had a long-term vision and groomed the backlog in the same way a good Product Owner would groom functional stories for a dev team. The team set sprint goals, conducted retros, tracked velocity and constantly sought process improvement.
In my next article, I will zoom out a bit and discuss data migration overall and introduce a new series of topics.

