

This is the second post in a series I am writing to convey lessons I have learned about Data Migration. My first post, introducing the topic of Knowing Your Data and describing steps 1 and 2, is here.
In the last post, we discussed the wisdom that, “If you manage data well, you can tackle any project, even if scope is enormous,” and proposed a basic process flow through which successful teams I have worked with approached the “Know Your Data” part of data migration. I discussed steps 1.0 and 2.0 in the first post. I’ll address step 3.0 in this article.

Step 3 - Map Data Objects
In the last post, I described a very deliberate activity intended to elicit specific direction from business stakeholders: how do you want systems to manage your data? In this section, I’ll describe a very different activity to identify what data should be migrated, in what form, to the new systems.
The big rule in this step is:
Only migrate data the new system needs; leave everything else behind!
As you will see, leaving data behind can be excruciatingly difficult. Rather than leave that up to chance, we propose a systematic approach. This process flow model illustrates a sub-process to step 3.0 that involves analysis of a given Business Data Object (BDO) as represented in both the source and destination (or target) systems. The sub-process starts at each end and works its way toward the middle.
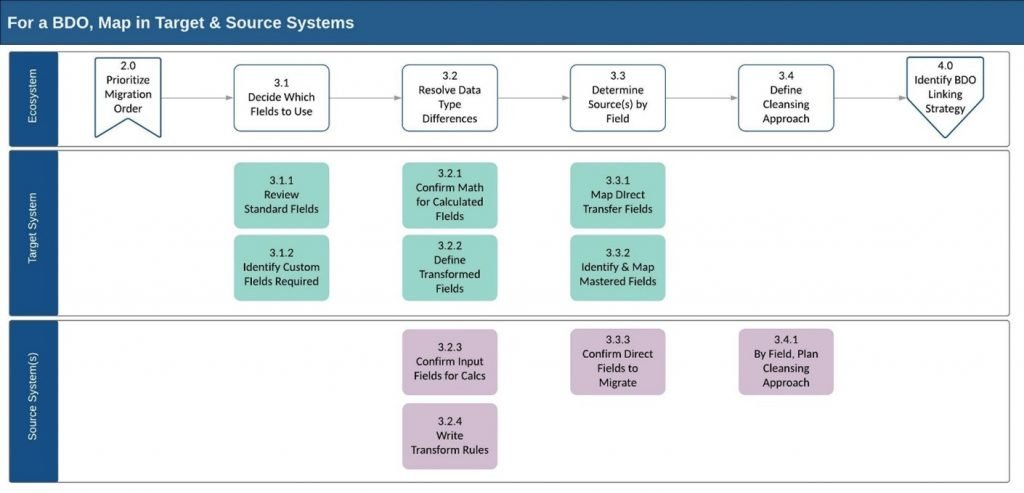
(This isn’t how I would normally draw a process flow, but it’s a nice, compact way to show all the steps in one graphic!)
For Each BDO...
Step 3.1 Identify which fields to use . A system migration is not just an IT exercise; it is an opportunity to transform a business. It is an inflection point where business teams and IT should work together to optimize how systems store and process data, and how business teams use process to achieve better results at lower cost. A critical factor is to decide what data to move and what not to move. In one project, the legacy system boasted a number of unstructured comment fields which contained some of the most valuable information about company assets. The fields had been added because the legacy system was bespoke, complex, and underfunded; adding functionality in one module frequently caused system outages as other modules broke. The comment fields were a crutch or safety blanket, but the team (rightly) decided not to migrate them directly. Rather, a cleansing effort was ramped up to translate the field into several structured fields that would be more manageable. The business process will need to change to accommodate the work of assigning values in the new fields, but should relieve burdens in current state, downstream processes that have grown up to manage the unstructured comments.
Step 3.1.1 Review the standard fields provided in the target system. If that system is provided by an external vendor, these might be considered the out-of-box (OOB) fields. Understand the field characteristics such as data types and validation rules. Discuss whether and how they’re presented in UI, whether required by the system, and what conditions might affect availability or visibility. The data migration team will need to work with the business and people documenting which fields will be used, which should be ignored, and which are candidates to receive migrated data. In my example from the previous section of the Customer object with 300 fields, you will need to plan for an extended commitment from the right SMEs on this work!
Step 3.1.2 Identify custom fields to support requirements that the system maker has not seen before. The same questions apply to custom fields as for standard fields: data types, validation rules, required or not, visibility rules, and whether they should receive migrated data. The additional challenge here is the rule I called out above: migrate only what you need. This step is not an open invitation to add dozens of fields. Even if the system provides very easy configuration-level support for new fields, you should approve fields only when the data cannot be supported in another way. In one project, there was vigorous debate over migrating a field containing a special alphanumeric code. This code was invaluable and meaningful to a small set of users, but inscrutable to most. A major goal of the new system was to push clearer data to the broad set of users, so the company decided not to move the special code field, even as a purely informational field.
Step 3.2 Resolve data type differences between the source and target systems. The typical cases will be replacing strings with integers (typically identifiers to a separate lookup table). A few of the more complex differences I wanted to call out are:
Steps 3.2.1 and 3.2.3 Confirm the math for fields that store calculated values. Migrating calculated fields from source to target systems requires careful analysis and planning. It is essential to understand how each system calculates a result. It is not enough to rely on common terminology, but to dig into precise details of how the formulas work and verify the scope of the data used – and then to validate that migration mapping results in the same values in any fields that will be used as inputs to the calculation. For example, in a financial system migration, both and old systems used several financial yield fields to determine whether a contract met company requirements. Each system used similar names for some yields. In some cases, names for yield fields in one system were flipped in the other system. In almost every case, analysis revealed that each system used different inputs to calculate each yield despite using similar terms. The customer and system vendor ultimately agreed on a set of customized yield fields to be added to the target system, while out of box fields would be ignored.
Steps 3.2.2 and 3.2.4 Confirm transformation logic for fields that do not map directly from source to the target system. This may be a case as noted above of replacing symbolic values with unique identifiers – we did this for many fields with lookup formulas in Excel during each of my recent projects. More complex cases involved use of multiple source fields to determine the value in a single target field, which required business SME input on business rules. These cases highlight the value of having dedicated resources to build and work in a transition environment; we’ll discuss this more in a future post.
Step 3.3 Determine source data by field between the source and target systems.
Steps 3.3.1 and 3.3.3 Direct Mapped fields. Depending on how different the source and target systems are, most fields you migrate will be directly mapped between the two systems. This is relatively straightforward work on the target end, but each project had numerous cases where the challenge was to determine which source field to use. In one case, a decades-old legacy system had been customized to have similar fields in different modules, maintained by different teams.
Steps 3.3.2 Identify & map master data fields. There will be fields that should be supplied by master data, which may be configured in the system as a different workstream from the migration effort. You may elect to change valid mastered field entries when moving to the new system. An extreme example I encountered involved an IP management system which stored asset location as a discrete text value, while the target system would store it as a unique identifier pointing into a taxonomy of locations. Determining the master values involved considerable research and debate about hierarchies, across a worldwide scope of locations. Mapping individual records then involved considerable disambiguation and testing.
Step 3.4 Define your cleansing approach. I will address cleansing and transformation overall in separate articles about the phases of migration and the value of having dedicated teams and technology. However, on a BDO-by-BDO basis, it’s important to develop a team consensus and plan to cleanse data for each specific data object. In a recent project we encountered the following:
- The core BDO was the Asset. There were millions of assets to track, and the asset record had over 100 fields. Of these, only about 20 are set by human action – the rest determined by various systems or processes. Of those 20 fields, 4 or 5 required extensive cleansing, which was amenable to scripted identification and proposed correction. The team was able to build a fantastic tool and hire contractors to slog through individual records; the tool allowed us to cleanse records rapidly and accurately.
- A related BDO was the Partner. There were thousands of partners, and a partner record required only two dozen fields. On the other hand, issues were not amenable to scripted correction as they required in-depth domain knowledge. The approach then consisted of spreadsheets and SME time, rather than tools and contractors.
- A critical assumption for the Asset data migration workstream was that there would always be additional curation work to do in the target system. Perfect data was an ideal judged impractical to achieve. The sheer volume of assets to migrate meant that the team needed to limit scope of cleansing activity to fix data that was truly bad. It could not validate the accuracy of every attribute, on every record.
We’ll continue the data migration conversation in my next post with Step 4.0: Identify Strategy to Link Data Objects.

