

This is the first in a series of articles discussing some common technical challenges with content migrations. The intent of this article is to describe a migration approach we often see our clients attempt and to point out a number of key problems and concerns associated with this approach. Hopefully this article will help you avoid some common pitfalls when you are planning a migration, building a custom migration tool, or evaluating an off-the-shelf tool. Later articles in this series will look at some ways to minimize these risks and develop a more robust and effective migration process.
Whenever you have electronic documents and data that need to be moved from one system to another, you have a content migration. Content migrations come in a variety of sizes and shapes. A simple migration may involve moving a small content management system (CMS) from one server to another without changing any metadata. Complex migrations can involve millions of documents coming from dozens of source systems on different platforms mapping into a new object model on the target system. However, regardless of the scale and complexity, most migrations start with the same basic approach. This typical approach is usually an iterative process with the steps shown below on Figure 1:
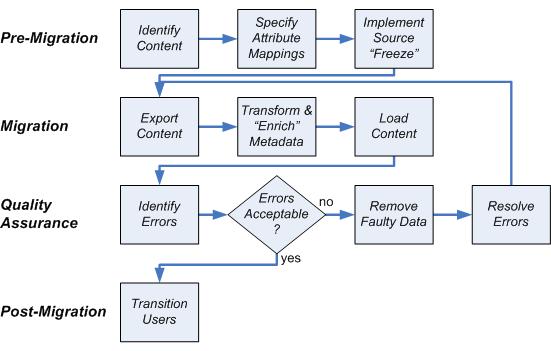
Figure 1:
Typical Migration Approach
While the approach diagrammed above seems straightforward and practical, our clients have found that things almost never go according to plan. This article will attempt to survey the primary technical challenges faced when performing a content migration using this typical approach.
Issues with the Typical Migration Approach
Most content migrations, big or small, simple or complex, are planned and executed using some form of the following process:
1. Identify Content to Migrate
The first step when conducting a content migration is to identify the content to be migrated. This may involve simply listing the directories on a file share, or it may be a set of queries into a content management system that isolate all of the objects of interest.
This step is simple in concept, but it can have huge impacts on how smoothly the migration runs. Most migrated data can be lumped into one of three categories
- A relatively small volume of super-critical content that needs to be migrated and made available to users again immediately.
- A large volume of non-critical content that needs to be migrated, but isn’t time-sensitive.
- An even larger volume of unnecessary content that is muddying up the source and should either be deleted or moved to a long term archive.
These three categories are usually intermixed in the source system so that they can’t be easily distinguished. They tend to wind up being migrated together which causes serious headaches in any large migration. Issues we’ve run into before include:
- Super-critical content must wait for the rest of the other content to be migrated. This is the source of most user complaints about the migration process.
- Migrating the archivable data in the third category slows everything down and passes the buck along to cause problems at the next migration.
- A business user will have rules in her head of how to collate content into these three categories. However, it is very hard to operationalize these rules using conventional migration tools. For example it is difficult to write a query to select “all financial records from the previous 5 years, except those for our Italian subsidiary and those owned by Sally Jones, but only grabbing major versions as long as the minor version is over one year old”.
2. Specify Attribute Mappings and Transformations
After identifying the content to migrate, you must specify which attributes in the target system will be populated and how. Because the data models in the two systems are frequently different, most attributes will either be mapped from existing metadata in the source system, or will involve a transformation of an existing attribute. An example of a mapping might be to take the ‘title’ attribute from the source and map it to the ‘title’ attribute in the target. An example of a transformation might be to take the ‘creation_date’ attribute in the source, add 180 days to it, convert the date format, and set it into a custom attribute called ‘review_date’.
Attribute mappings and transformations get lots of attention during the planning phase. Migration consultants frequently brandish mapping spreadsheets, transformation formulas, and other tools that purport to make the attribute mapping easy. When it boils down to the execution, however, data quality and object model differences frequently mean these tools address only a fraction of the problems with the metadata. Other issues we have seen on our clients’ migration projects include:
- Most organizations understand that the metadata associated with content in a repository is of poor quality. However even this pessimistic appraisal often underestimates the scale and difficulty in resolving issues with data quality. Common issues we see include missing values, inconsistent values, values out of expected range, and lack of conformity with standards.
- Assessing data quality at the beginning of the effort is a worthy yet unattainable goal; statistically sampling data in advance leads to a false sense of security since most problems only become apparent during import or validation.
3. Implement a “Freeze” in the Source System
Once the user has defined the content and specified attribute mappings and transformations, it is time to define a freeze window during which changes, additions, and deletions in the source system are not allowed. This freeze may be accomplished by physically rendering the source system read-only or may involve restricting changes only to administrators.
At first blush, this sounds fairly simple and straightforward. But the implications of freezing an active business content management system are significant:
- Business processes which create or modify content are brought to a screeching halt.
- The content freeze must last until the migration is complete. This freeze period is a huge burden on the users of the system, as they are prevented from performing important work.
- The length of the freeze is almost always underestimated. Problems with data quality, and issues with mapping and transformation won’t get discovered until you try to load and validate data in the target system.
- During the freeze, users will find another way to keep their business running using ad hoc workarounds. This is bound to cause headaches when you want them to come back into the new system.
Export and Transport Content
Following the freeze, the next step is to export the relevant content to a staging location for temporary storage. Exporting and transporting the data doesn’t often lead to many problems of a technical nature, but there are some pitfalls to avoid.
- Often the source and target repositories are located across a slow network connection. When this occurs it may be necessary to transport the content and metadata by physically shipping the data on a hard drive, DVD or other storage medium.
- If you have not been able to screen out the archivable content, then the data to be transported is much larger than is necessary.
- Some types of data, such as version stacks and virtual documents, require careful sequencing of export, transform and import in order to maintain the proper references between objects.
5. Transform and Manually “Enrich” Metadata
After exporting the content and metadata, the next step is to actually perform the attribute mappings and transformations specified earlier. These are a series of programmatic steps to get the metadata ready for import into the target system.
Many migrations involve importing content into a system with a richer and more sophisticated object model. This requires that business users manually “enrich” metadata through manual or semi-automated process. “Enriching” the data requires users to look at the metadata and populate new mandatory attributes in the target, or perhaps to improve the overall quality of the metadata. There are a number of issues that arise when running the attribute transformations:
- One example of a difficult attribute to map is version labels. Version stacks are frequently complicated by one or more of the following: branched versions, missing versions, having to derive a stack from a file system naming convention, and converting to a target system which uses a different numbering scheme.
- Certain attributes can be very tricky to migrate correctly because the CMS controls the value. An example is the modification date (r_modify_date) in Documentum. Sometimes you may wish to maintain the r_modify_date from the source system to the target. This process is impossible to do through the Documentum layer as updating the r_modify_date field is itself a modification and will cause the date to be set to the time of the import.
6. Load the Content
Now that the metadata is ready, it’s time to load data into the target. This process can take from minutes to days. The actual time depends on the number of documents, the processing horsepower of the hardware and the rate at which the migration tool can import them. Typically during this step, run-time errors are encountered which require remedial action. Examples include adding a referenced user to the target system or eliminating documents with corrupted content.
While loading the content should be one of the most straightforward steps in the process, it is often one of the trickiest. Some of the issues we frequently see include:
- Content loading is often the first step in the process where any error checking and validation takes place. If a document owner doesn’t exist in the target system, an error will be thrown during the import. If an attribute value is too long for the field in the attribute, it probably won’t be seen until the object is imported. This is terribly late in the process to get the first real feedback on the design of the solution.
- Some tools try to increase the throughput by interacting directly with the database. However, skipping the application layer can lead to irreparable errors in attribute values, ownership, lifecycle states, permissions, and just about any other aspect of objects in the target system.
- Often, documents in the source system will be in a state that can only be reached by interacting with the document using the CMS tools. An example of this is occurs when a document within Documentum is promoted from its initial lifecycle state to an intermediate lifecycle state. Often these intermediate states are “non-attachable”, meaning that it is illegal to import a document into that state – the state can only be reached by, say, routing the document on workflow. You will want to consider how to deal with documents in an intermediate state.
- Another issue in migrating into Documentum repositories is that documents become immutable when they are not the current version. For instance, the API commands necessary to set the lifecycle state in the previous example must occur when the object is considered current. If you are migrating previous versions of documents, then your migration tool needs to be able to handle this immutable state.
- Many objects to be migrated will depend on other objects before they can be imported. Examples of this include: virtual documents, relationships, users, groups and ACLs. Migrating these objects into the target creates certain technical challenges. It requires the creation of a set of target objects that have interdependencies and potential circular relationships. The migration process needs to be able to properly sequence the migration of these objects so the correct dependencies are maintained.
7. Identify Errors in the Migrated Data
Once the content has been loaded in the target system, the migration team attempts to identify errors in the migrated content and metadata. This is accomplished either through querying the target programmatically or by manually sampling individual documents.
Identifying errors is usually when the business users first get heavily engaged in the migration process. Through a combination of automated and manual sampling, these users review the data and report the number of errors and issues encountered. With most migrations, the final goal boils down to reducing the number of errors to a manageable amount. Our clients have run into a number of problems at this stage, including:
- If the migration is being conducted in conjunction with development of a new system, users may report errors in both the migrated data as well as issues in the application itself.
- Business users are usually less engaged in the mapping process, but suddenly become razor sharp when they see it in the target system.
- It is very difficult and demoralizing to first discover issues this late in the process. Finding and correcting problems at the last minute always blows the migration schedule.
- Sometimes, when a transformation error is discovered (usually during the sampling or validation steps), the error identified is just the tip of the iceberg. It really represents a much bigger issue with the mapping or transformation rules. If this is the case, how do you ensure that all documents have been fixed without literally checking every document?
8. Remove the Faulty Migrated Data
When errors are identified, it is necessary to unload all or part of the migrated content so that the errors can be addressed. The faulty migrated content must be identified and removed from the target to avoid having inaccurate data available to end users. This step is fraught with danger, particularly in a live target system. Some of these risks include:
- It is very tricky to identify all of the correct content to remove while ensuring that no live data created by users is removed inadvertently. Timestamps won’t suffice all by themselves.
- It’s all or nothing. One error usually causes you to completely unload the migration, fix the problems, and reload the entire set.
- The time this process adds to the migration is always greatly underestimated.
9. Resolve Errors and Repeat Process until Error Free
When errors have been identified in the source, a number of remedial actions may be taken. Issues discovered during the validation step may be corrected by a variety of methods: modifying attribute transformations, resubmitting data for manual enrichment, changing the criteria used to identify content or by making changes to the target system and rerunning the export. Often the solution is some combination of the above.
- Users are most familiar with their existing source system. They will want to resolve the issues by fixing data in the source. Then you are truly back at square one and must go all the way back to the export stage.
- It is often a challenge to prove, to yourself and others, that all documents to be migrated actually exist in the target.
- Object counts are helpful, but many objects are often skipped intentionally during the migration due to data quality issues. Distinguishing between an object skipped for legitimate reasons and one that was left out can be difficult.
10. Transition Users from the Old System to the New
So now you’ve finally done it! The users are trained and ready to go, the data is in the new system and all of your data quality issues have been addressed. It is time to transition your users from the old “frozen” system to the new one.
This transition involves two steps: 1) rendering the previous system invisible or decommissioning it, and 2) making the newly migrated documents available to users in the new system. Although your migration may be complete, it is not time to take it easy yet. There are still issues to consider during the transition:
- More than one system of record for a particular document potentially exists during the freeze period. This may result in a legal issue in a regulated industry. It may be necessary to prevent in-progress migration from being visible in the target system.
- If your freeze period has lasted for a long time, your users will have been storing up their changes and will want to make them all at once. Since you’ve just turned on the system you are potentially still working out the kinks. The load can physically overwhelm the system or at least overwhelm your process for resolving issues.
Hopefully this article has given you and good sense of the issues and problems inherent in the typical migration process. This process has been used countless times to move content between content management systems, and into CMS from file systems. For small and simple migrations the issues above may only represent minor annoyances. When the migration is large or complex, however, they can become true show-stoppers.
If you find yourself out on the ledge, don’t worry. We’ve written an article that discusses an approach which we have found will resolve these issues and make your migration projects as painless and uneventful as they can be.


