

Introduction
Migrating enterprise content from one system to another requires undertaking two separate yet intertwined migration efforts: moving the actual content files and moving the related data. When planning a migration initiative, it’s easy to overlook the data migration that is implied in the process. Yet the majority of problems encountered during content migrations are actually problems with the data, which includes the obvious metadata as well as the not so obvious data components such as ownership, security and permissions, folders, workflow and lifecycle state, version stack, and audit history. This article describes the types of problems you can expect to see when moving the content’s data and explores options for planning and performing the migration of the data that is related to your content.
How Big is the Iceberg?
Upon first glance, migrating content from one repository into another – or even from a filesystem into a repository – seems simple. There are tools that allow you to map the attributes from the source system to their corresponding attributes in the target system, then push a button and watch the content move. However, in practice it’s rarely this simple. To understand the potential pitfalls in even the simplest content migrations, let’s turn to the familiar iceberg metaphor.
Figure 1:
The Tip of the Iceberg
The visible portion of the iceberg represents the attributes that can be mapped in a straightforward fashion. For example, object_name in the source system might map to object_name in the target system, while doc_no in the source system might map to document_number in the target. But lurking below the waterline is a continent of challenges and issues – issues related to attribute transformations, attributes requiring enrichment, and exceptions. We can cast these challenges as different strata in the iceberg; the deeper you go, the more complex or challenging the issues become.
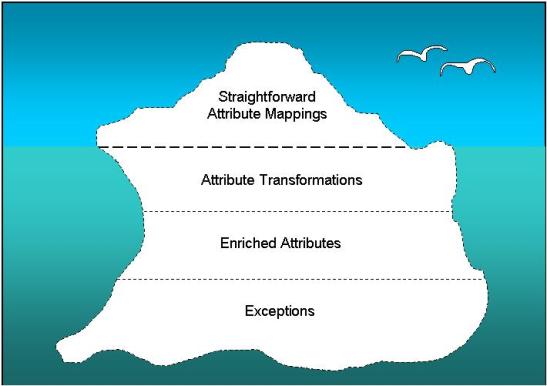
Figure 2:
The Full Iceberg
Dealing with the Iceberg
Each layer of the iceberg presents its own unique challenges and must be planned for differently. The one common theme is that your approach and plan must anticipate that you will find problems once you begin looking at migrated content and data in the target system.
Straightforward Attribute Mappings
Many of the attributes in your source repository will map seamlessly to your target repository. Since these mappings are, well – straightforward, this part of your migration specification usually gets the most attention. Your intuition for how to plan this part of the migration will probably serve you well – it boils down to doing a little bit of analysis as you plan.
At Blue Fish we’ve developed a set of best practices that has served us well across a broad range of content migration efforts. Start with your target repository’s object model and understand where each attribute will come from. If your source system is a Documentum docbase or another formal content repository, it’s likely that many of the attribute values will map directly from attributes in that system. If your source is a filesystem, there will be fewer explicit attributes to pull from. In either case, some values may require transforming, which we will discuss in the next section.
Next, analyze your source documents. Does your legacy system have all the metadata that the target repository requires? If not, we deal with those missing values in the next two sections.
Assess the quality of the metadata. Do the values exist? Are they complete? Are they valid? Are they in the expected format? For example, are all dates “mm/dd/yyyy”, or are some “dd/mm/yyyy” or “dd-mm-yyyy” or “dd-MMM-yy” or “Month dd, yyyy” or “mm/dd/yyyy hh:mm:ss” and so on. Were users consistent in how they tagged and classified documents? Did the legacy system enforce consistency? An invalid or incomplete value moved into a non-critical target attribute may be a nuisance, but a missing or invalid value moved into a mandatory target attribute will cause your migration to fail.
Things to watch out for:
- A migration is a great opportunity to do some housekeeping to ensure that you migrate only relevant content. How will you identify and exclude documents that you don’t want to migrate? For example, will you migrate only major versions (v1.0, 2.0, 3.0…) and leave behind the minor revisions (v1.1, 1.2, 2.1, 2.2…)? Should you screen out documents for products no longer in service? Will you archive documents more than 7 years old instead of migrating them to the new system?
- Having analyzed the quality of your metadata, don’t place too much reliance on that analysis (more on this later). You must plan to encounter exceptions resulting from inconsistent or incomplete metadata values and be prepared to handle them when they arise.
Attribute Transformations
The first submerged layer of the iceberg consists of the complex mappings we call attribute transformations. For example, if in the source system the author_name is “John Smith” but it must be “Smith, John” in the target, the value must be transformed during the migration into the new format.
To use a transformation, you must be able to programmatically derive the value of the target attribute from information in the source repository, such as the document’s folder path, owner, or other attributes. Many transformations are expressed in terms of conditional statements. For example, you may need to set an archived attribute to true only if the document is more than 3 years old.
Some common types of transformations we’ve seen include:
- String manipulation – repeating the example above, in the source system the author_name is “John Smith” but it must be “Smith, John” in the target
- Date arithmetic – take the creation_date attribute in the source, add 180 days to it and set it into a target attribute called review_date
- Combining attributes – the first_name and last_name in the source system are combined to create the target value called full_name
- Splitting attributes – splitting street address, city, state, and zip code out of a single address attribute in the source system and putting them into individual target attributes
- Parsing – starting with a date field with the format “01/31/98”, pull out the year and reconstruct the 4 digit year of 1998
- Deriving attribute values from other attributes – if a document is in a source system folder called “Invoices”, then the doc_type is “invoice”; if the file name contains the string “-APP”, then the doc_status is “APPROVED”
Planning for this part of the iceberg is similar to planning for the straightforward mappings. In fact, you can often do the analysis for transformations at the same time you are analyzing for the straightforward mappings. The main reason that we think of transformations as more challenging is that they can frequently get out of control, adding a lot of complexity to what you may have thought was a simple migration. It’s not uncommon to build up a transformation that evaluates the values of three or more source attributes. In a recent migration, I recently had a transformation that required evaluating three document level attributes and one folder level attribute to determine whether a document’s status was “draft” or “released” in the target system.
Things to watch out for:
- Inconsistently applied naming conventions – if you are deriving an attribute value from the name of the content file, don’t expect 100% compliance with the stated naming convention. If human beings created the file names, there will be exceptions.
- Attributes that were not used for their intended purpose – some of the more interesting exceptions arise from well-intended users hijacking attributes and using them for something different on “just these 5 documents” or for “just this one customer”.
- If you use the folder path as part of your transformation, how will you deal with documents that are linked into multiple folders?
- Mappings that require complex transformations (if you have these cases, you need to know before you select your migration tool, since most tools can’t do this sort of thing). For example, version stacks that need to be joined or split, separate documents in the source that need to be treated as renditions of the same document in the target, and attribute values from the current version needing to be applied to all versions in the version stack.
Enriched Attributes
After you deal with attribute transformations, you’ll face an even greater challenge: target attributes whose values cannot be mapped or programmatically derived from information in the source repository. Typically, this is the case when either the source system has no corresponding attribute or the source attribute was not mandatory (and therefore not populated). Enrichment is basically a last resort when there is no programmatic means for providing the target attribute values.
These attributes require users to “enrich” the data in a manual or semi-automated fashion, supplying the missing data based on their knowledge of the content, the system, and the related business processes. For example, if a document is missing its title, the author of that document must go back and add a title before the document can be migrated.
When planning enrichment activities, give some thought to who is best suited to do the work. Since enrichment activities require users with an understanding of the business context, plan to have the right business user(s) enrich the right set of attributes. You can divide the content into enrichment groups and route each group to the user(s) with the relevant knowledge. This is especially useful if the schedule is tight since it allows you to parallelize the enrichment process, Or if knowledge about specific attribute values is segmented across departments, you can slice the enrichment process and have different users enrich different attributes. And make sure you work with the appropriate managers to allocate time for the selected business users.
Even though knowledgeable users are providing the missing values, don’t expect them to get it right on the first try. Build in safeguards. For example, if you are using an Excel spreadsheet to capture missing attribute values, use drop down lists to ensure consistency and completeness and avoid data entry mistakes. If a drop down list must match the data dictionary in the target system, make sure you export the latest version of the list before starting enrichment, and periodically refresh the list if needed.
In addition to drop down lists, provide a default value so that the attribute value cannot end up blank. As a last resort you could default to the object owner’s name for future resolution. Have the enrichment process provide immediate feedback for potential errors. For example, use the built-in data validation capabilities of Excel to prompt the user to correct errors immediately. And lastly, be prepared to validate or otherwise check the results of enrichment activities.
To determine the duration of the expected enrichment activities, run a sample set through your enrichment process. Since attribute enrichment is basically a linear process, you can safely project a completion date based on the time it took to complete the sample set, after adding in a reasonable amount of schedule contingency.
Don’t try to use a statistical sample (again, more on this later). Instead, query your source repository to determine exactly which documents are missing necessary attribute values. You’ll need a separate query for each attribute. In a Documentum repository, an example would be “select * from dm_document (all) where title is nullstring”.
Finally, select a migration tool that directly consumes the enriched attribute values. This speeds up the process and avoids translation or transcription errors.
Things to watch out for:
- Don’t forget about older versions – just because the current version of a document has all its attributes doesn’t mean that the older versions do. These older versions will cause the migration to fail if you don’t have a way to deal with them.
- If your migration tool uses a staging area between the source and the target, you might be tempted to enrich the data at this point. Beware, because if you have to export your data again, you’ll overwrite your previously enriched attributes.
- Business users are busy people and will not be thrilled with having to enrich their data, especially their old data they don’t use anymore. Plan your diplomatic request for their time and allocate more time than you think it will take.
Exceptions
Now we are into the deepest and darkest region of the iceberg. This is where most migrations go wrong, because the approach failed to expect the unexpected. Most exceptions won’t be discovered until you start migrating data into the target repository. Identifying and addressing them is where you will spend most of your time, so you’d best plan for it.
The following list of examples is by no means complete but will give you a flavor of the variety and severity of exceptions you can expect to encounter.
- Documents with missing or incomplete attribute values
- Unexpected formatting, such as inconsistent capitalization and white space at the beginning of a string
- Attributes with values that don’t exist in the target repository, such as owners who have left the company or IDs for products that have been discontinued
- Documents whose file names don’t conform to naming conventions or otherwise break your attribute transformations
- Unexpected data, such as a company name in the author field
- Immutable objects – by default, objects in a Documentum repository become immutable when they are not the current version.
- Interdependencies and potential circular relationships with users, groups, ACLs, relations, and virtual documents – each object can have dependencies on other objects in the source repository as well as the target repository. For example, if you are migrating the document owner as part of the document object’s metadata, that owner needs to exist as a valid user in the target system before you try to import the document.
- Migrating the workflow state of a document that is somewhere between the initial and final workflow states – usually these intermediate states are “non-attachable”, meaning you cannot set the document to this intermediate state after importing it.
- Old content files whose file format or version is not supported by the target system
There are four ways of dealing with exceptions:
- Correct the source data – Sometimes you can resolve an exception by updating the source data. If a document’s name doesn’t conform to the naming convention, update it so that it does. This approach may not always work, since the source system likely contains immutable objects or regulated content that can’t be changed without an approval process.
- Update the migration specification – if your migration tool supports conditional transformations, you may be able to resolve some exceptions by updating the migration specification to treat the document in question differently. For example, if a document does not conform to the naming convention, you can encode the migration tool to detect this case and apply a different naming convention. The danger of this approach is that your migration specification can quickly get out of hand and will soon have so many exceptions encoded into it that debugging and maintenance become a nightmare.
- Further enrich the metadata – if your migration tool supports external enrichment, you may be able to resolve your exceptions by manually specifying the exact values for each exception. This is likely the most time consuming approach.
- Do nothing – at some point, the effort it takes to handle an exception may not be worth it. An example might be a document is no longer in active use and is just being migrated for archive purposes. If it has several exceptions or requires enrichment, you may decide not to migrate the document after all, or to migrate it into a “parking lot” folder to be dealt with at a later time.
One of the things that makes exception handling particularly hard is that some exceptions will be “hiding behind” other exceptions. What I mean by this is that a document might have two exceptions, but you won’t know about the second exception until you resolve the first exception. For example, you may find a set of documents whose document_type attribute is not populated. To resolve this exception, you decide to change your migration specification, populating the document_type based on the naming convention of the folder the document is linked into. You then re-run your migration, only to discover that some folders don’t conform to the naming convention.
We’ve found the most effective way of dealing with exceptions is to find them early and fix them iteratively. Start performing migrations right away, perhaps into a test environment. Then run your migration again – you’ll find new exceptions that need to be resolved. Plan on having many, many iterations. Most migration tools can’t process documents incrementally, so either select one that can or plan each iteration to have enough time to roll back your migration and rerun it from scratch.
At Blue Fish, we use a methodology we call Agile Migrations, where we perform frequent, incremental migrations during which we only re-migrate the small number of documents that have changed. Having worked on migrations for years, I can tell you that this beats the old “big-bang” approach hands down.
Additional planning steps that will keep you out of trouble include:
- Keep an exception log so that you can track all the issues that need to be resolved
- Plan on keeping detailed records of the status of each document – your business users will want to know which documents have migrated successfully and which still have issues that need to be resolved
- Try to segment your high priority documents from your low priority documents, migrating the critical documents first. The low priority documents can be migrated on a different schedule.
The Perils of Sample Data Sets
One of the most common migration planning mistakes is to employ an approach that runs one or more sample sets through the migration process and then projects a migration timeline based on the analysis of the samples. If you’ve learned one thing from this article, hopefully it is that it’s very hard to predict how many errors and exceptions you’ll encounter during the migration process. Even a statistically valid sampling of the data will give you a false sense of security since you are certain to run into exceptions that were not found in the sample set.
We learned this lesson the hard way. Several years ago we embarked on an effort to migrate 600,000 documents from three Documentum source repositories and one fileshare into a new consolidated Documentum repository. Determined to exercise due diligence in the planning stage, we started off by compiling a list of 150 assumptions about the state of the content and metadata. For example, we assumed that every document had an object name. We scripted DQL statements and programmatically validated all of these assumptions.
After validating the assumptions, we divided the documents into 350 batches. The plan was to run 20 of the batches, representing 6% of the total content to be migrated, through the migration process. We expected this test drive to uncover 80% of the exceptions. However, all 20 batches had their unique problems that required specific handling. At this point we realized we could not predict the number of exceptions and shifted our approach to expect exceptions and facilitate addressing them as they arose.
In summary, the smart and sane approach is to expect exceptions and be prepared to handle them when, not if, they arise.
Conclusion
Before tackling a content migration initiative, remember the iceberg. The straightforward attribute mapping is just the tip. Each layer has its own challenges and requires different planning. Exceptions take most of the time, and planning to respond quickly to the exceptions boils down to three things:
- Expect exceptions.
- Have the right resources available and prepared to respond to the exceptions when they arise.
- Migrate early and often, finding and resolving exceptions iteratively.
Following this approach and setting the right expectations up front will prepare everyone for the challenges. When data issues and exceptions are spotted in the target system and quickly addressed, the migration team and business users alike will realize the process is “working as designed”. Everyone will see the progress and feel confident that the migration effort will be successful and will be completed on time. And you will feel a sense of accomplishment and relief knowing you successfully charted the iceberg and navigated around it instead of colliding with it.
To learn more about the tools and processes we use here at ArgonDigital, visit the Content Migrations section of our Web site.


