

Introduction
With the release of Migration Workbench™, ArgonDigital has changed the way we perform content migrations projects. Key new capabilities such as true incremental re-processing of changes, dynamic cutover, rules-based transformations, and live-to-live migrations have dramatically reduced the time and cost of even the most complex migrations.
But our clients aren’t stopping there. These new capabilities are being used to solve a variety of content management challenges across the enterprise.
Use Cases
Bulk Archiving
There is a common need for owners of Content Management Systems (CMS) to archive documents. This need may arise from the need to comply with records management policies, or as part of a larger consolidation project. Mergers and divestitures may also require the bulk archiving of content. Some types of CMS perform better when object counts are kept low, and so archiving older versions of documents can help to improve system performance.
Generally this task is performed manually by system administrators, and often using very blunt tools. A common practice is to use a tool that specifies the documents to be removed by query. The administrator then exports the documents to an archive system and deletes them from the source system.
In order to archive a particular piece of content and not another similar object, you need to be able to identify it with a specific query. This does not provide the level of granularity often needed to select all the documents, and only the documents, to be archived. If the archive system is on another platform, an entirely new approach must also be found to load and verify the archived data. The result is often a large amount of custom programming requiring a high level of expertise to operate and maintain.
Applying Migration Workbench to this task, even very complex archiving requirements can be quickly configured as migration rules. For example, you may wish to archive documents that meet the following characteristics:
- located in a specific folder,
- older than a certain date,
- inactive for greater than a year,
- having version numbers less than the current major version,
- only moving the original document to the archive, and
- deleting all pdf renditions from the source.
Using Migration Workbench, writing these requirements as migration rules is easy! First, list the folder as the batch criteria for documents that are candidates for archive. Next, write simple rules to identify 1) documents created since the cutoff date, 2) active documents, 3) documents inactive for less than a year, and 4) current documents. Indicate that these documents are not to be migrated. The remaining documents are those to be archived. The last step is to write a rule to only copy over the original document and not renditions. Migration Workbench takes care of the rest.
Because migration and cutover are two separate activities in Migration Workbench, the user can also preview the documents to be archived prior to making the move permanent. Migration Workbench provides reports that detail exactly which documents are in what state. And using the incremental migration approach, mistakes can be quickly and easily rectified by simply changing the rules and rerunning the tool.
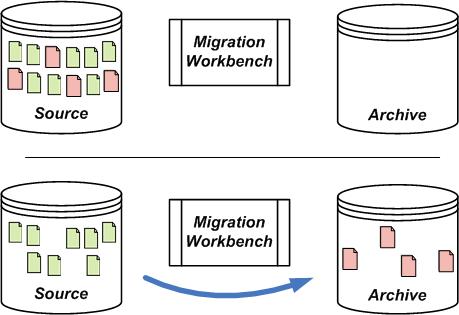
Figure 1:
Using Migration Workbench to Perform System Archiving
Continuous Archiving
Many users want a way to move old or obsolete documents from their CMS to an archive on an ongoing basis. The criteria for moving documents into archive may be based on metadata values such as document age or document status, or it may be based on a user actively selecting to archive the document. This need is very similar to bulk archiving, but is a continual archiving process rather than a big bang event.
As with bulk archiving, Migration Workbench can be configured with migration rules to correctly identify, move, and cut over content to the archive. However, you can also take advantage of the incremental processing capabilities of Migration Workbench to create a continual archiving process. By setting Migration Workbench to run on regular intervals, it effectively monitors the CMS for changes to content or metadata that qualifies that content for archiving. System administrators can easily see and audit the results of this process using standard Migration Workbench reporting.
Publishing Content for Broad Consumption
Many organizations maintain separate content management systems for the authoring and publishing of content. The two systems are frequently built on two different repositories, or even on two different content management platforms. As an example, one recent ArgonDigital client wanted a one-way publishing solution to push finished documents from their authoring system, hosted on Documentum, to a read-only system used for distributing training documents and SOPs, hosted on their portal platform, Sharepoint. The authoring system contained all the rich content creation, editing, and workflow of Documentum, but was only accessible to a small subset of content authors. The read-only system was hosted on Sharepoint, reducing the need for additional Documentum licensing, as well as providing security for the authoring system. Because it is cross-platform capable, Migration Workbench was used to automatically publish content from the authoring system to the broader use publishing system.
This case is similar to the case of continually archiving documents, but instead of permanently moving objects over and removing them from the authoring system, individual versions are moved to the publishing system based on status without deleting them from them the source. For example, suppose a content author’s workflow has three states: Draft, Published, and Retired. Initially a document has version 1.0 in Published state and 2.0 in Draft state. Rules in Migration Workbench could be written to select only documents in the Published state. On the initial run, Migration Workbench would pick up version 1.0 and push it from the authoring system to the publishing system. Later, when a user publishes version 2.0, which changes version 1.0 to the Retired state, Migration Workbench will pick-up that incremental change, delete version 1.0 from the publishing system, and push over version 2.0 in its place.
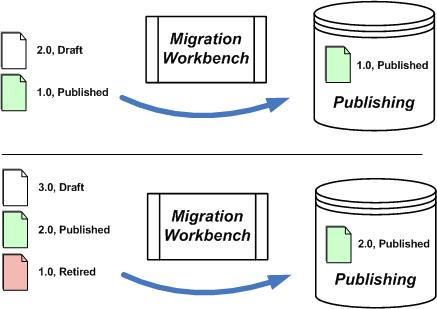
Figure 2:
Using Migration Workbench in a Publishing Role
Content Receipt and Tracking
Many organizations want to provide a way for their partners and vendors to contribute to business processes without giving them direct access to critical internal content management systems. For example, a firm may need a way to receive receipts processed by an external payments management firm, or import lab data collected by a contract laboratory. Migration Workbench can be used to receive this content, validate the metadata, and provide a confirmation that the content was properly processed.
The first step in providing a solution like this is to set up a content ‘drop zone’, such as an ftp site or a document upload web page. Partners can use this to drop off content files and provide the associated metadata for that content in the form of XML or CSV files. Using an upload web page allows for the creation of a database-backed web form, further simplifying the partner’s upload process.
Migration Workbench is then run on a periodic basis to monitor that drop zone for new or changed content. Validation rules are used to check that mandatory data fields are populated and all data is within expected ranges. Migration Workbench keeps a record of what content was imported correctly as well as what content failed the validation rules and was placed in a holding state. Standard reports can be used to easily identify content validation issues so the partner can take corrective action. The next time Migration Workbench executes, incremental processing will identify the changes and re-process the content. Once the content is successfully received and imported to the CMS, a dynamic cutover strategy can be configured in Migration Workbench to delete the content from the drop zone and send the partner a receipt confirmation.
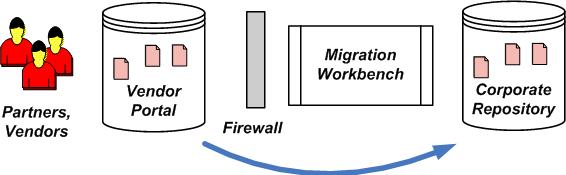
Figure 3:
Using Migration Workbench to Import Documents from External Vendors
Receiving Documents from Scanning Systems
Many large organizations wrestle with processing extremely large volumes of documents created by scanning systems. Common examples of these solutions include scanning of insurance claims, invoices, and trade confirmations. The scanning system typically generates an image file of the document and places that file into a file share. The scanning system’s OCR software then parses metadata values from the body of the document and creates a metadata record in a database, XML, CSV, or similar data file.
Similar to the case of content receipt and tracking, Migration Workbench can be configured to recurse through the file share where the scanned images are located, identify new or changed content, and look up the metadata that corresponds to that piece of content. Transformation rules easily map that content and its metadata to the CMS’s schema, and dynamic cutover rules can be put in place to remove these from the file share once they are imported into the CMS.
Loading Test Systems with Production Data
Many well intended system releases and updates are immediately plagued by defects and issues for the simple reason that they were tested with data that was not representative of real world production data. Content management applications, in particular, are likely to encounter data inconsistencies and errors that simply cannot be anticipated with artificially fabricated test content and data.
With Migration Workbench, application developers have the ability to easily migrate select subsets of content and metadata from live production systems back to their test systems without impacting production system availability. As testing progresses, inclusion and exclusion rules can be written and adjusted to change the type and quantity of production documents being used in the test system. Migration Workbench’s incremental functionality also allows for the test data to easily be kept up to date with content in the production system, if needed.
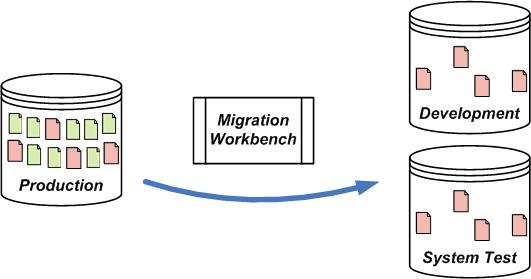
Figure 4:
Using Migration Workbench to Populate Test Data
Assembling Document Bundles for Submittal
For companies in regulated industries such as pharmaceuticals, there can often be thousands of documents associated with a single submittal to a regulatory agency. Using Migration Workbench’s rules-based document selection capabilities, it is easy to configure individual export batches to collect all documents and metadata associated with a single regulatory submission. This could also include the selection of appropriate versions and renditions for assembly.
Another similar use case is the publishing of engineering drawings. Engineering organizations often create thousands of engineering drawings as work product, and face significant liability if the wrong versions were to be issued to their clients. There is a substantial need to be able to accurately bundle the correct documents in various configurations (site drawings, structural, electrical, plumbing, etc.) and ensure the correct versions are consistently used.
The rules-based approach used by Migration Workbench gives you the power and flexibility to precisely define the documents and data to be packaged. Additionally, incremental processing means that you can easily respond to follow-up requests for documents that have changed since the last submittal. Re-running the export will update the submittal with the just documents that have changed or are new.
Metadata Quality Analysis and Reporting
“How clean is my data?” or “What errors will I get if I run this migration batch?” are common questions faced by CMS administrators. Migration Workbench can be used to make this analysis easier.
Data validation rules can be put in place early in the migration process, even before transformation and mapping rules are defined. Migration Workbench can be configured to run in a ‘test mode’, where all of the rules are evaluated and reported on, but no content or metadata is actually imported into the target system. This gives the user a preview of what exceptions and issues to expect without incurring the time expense of actually importing content.
Conclusion
From the examples above, it is easy to see that Migration Workbench can be used to solve a variety of content management problems above and beyond just migrations. Capabilities such as true incremental re-processing of changes, dynamic cutover, rules-based transformations, and live-to-live migrations provide users with the flexibility to create innovative solutions for a broad range of CMS challenges.


