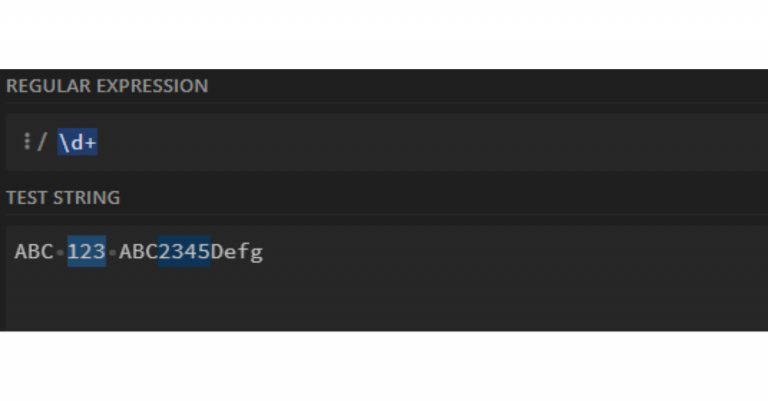
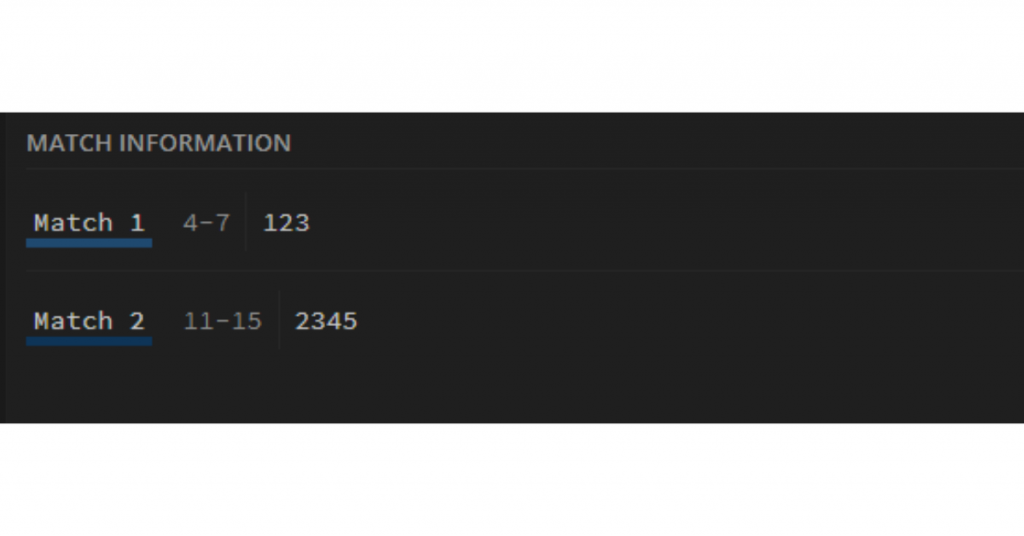
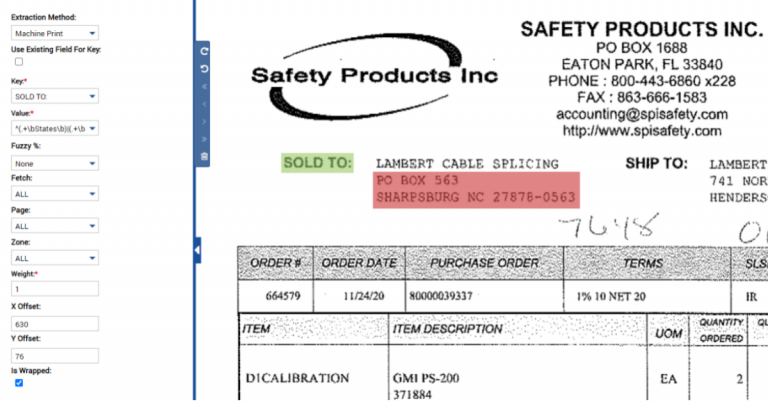
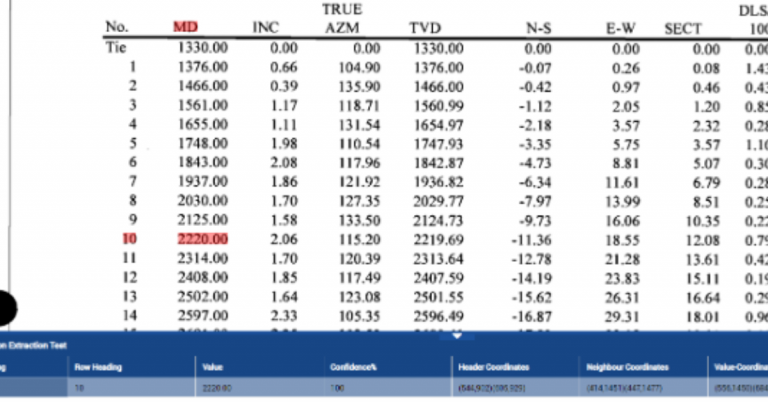

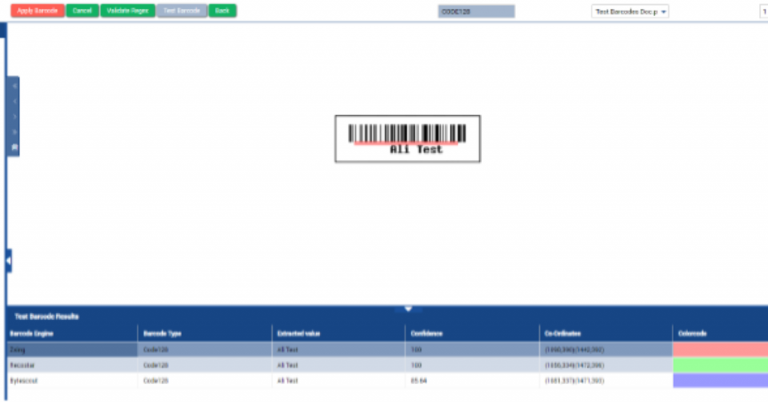
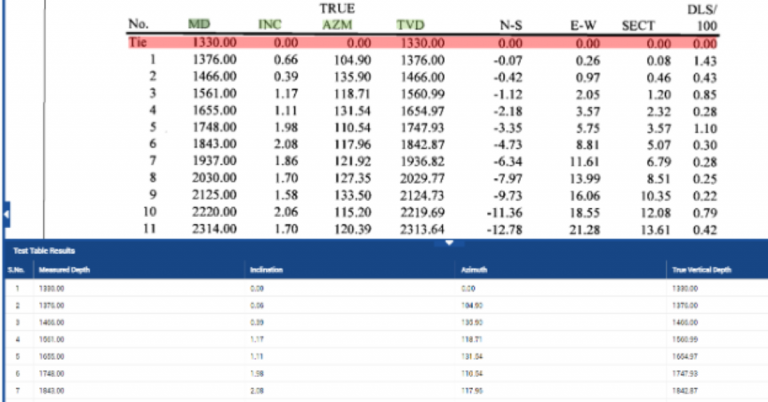



How AI is Revolutionizing Software Development If you’re managing software projects, you know the holy trinity of success: speed, accuracy, and scale. But achieving all three simultaneously? That’s the tough

At ArgonDigital, we’ve been writing requirements for 22 years. I’ve watched our teams waste hours translating notes into requirements. Now, we’ve cut the nonsense with AI. Our teams can spend
