
Introduction
This article explores Documentum search features with a heavy focus on the Java DFC APIs related to search.
Documentum product manuals are invaluable resources in coming to understand these concepts,
but in many cases they are missing important details–details that you would otherwise have to
learn via prototyping and trial and error. In this article I’ll attempt to cover these missing
details while providing a focused overview of DFC search and query features.
The Simple Query API
DFC’s simple query API allows you to execute queries expressed as DQL strings. Here’s an example:
public IDfCollection getLargeDocuments(IDfSession session)
throws DfException
{
IDfQuery query = new DfClientX().getQuery();
query.setDQL(
"SELECT * FROM dm_document " +
" WHERE r_full_content_size > 1000000");
return query.execute(session, IDfQuery.DF_READ_QUERY);
}
Here, we create an IDfQuery instance using the factory method IDfClientX.getQuery(). Then we populate the query with a valid DQL string and call the query’s execute() method with an IDfSession instance.
DFC documentation refers to this as “the simple query API.” There are some significant limitations to this API:
- Only queries on a single repository are permitted. The target of the query is implicitly the default repository of the provided
IDfSession. - Only Documentum repositories can be queried. You cannot query an external, federated (ECIS) source.
- There is no support for programmatically building queries; only explicit DQL query strings are supported.
- Executing a query is always a thread-blocking operation; that is, the thread issuing the API call blocks until the query results are returned.
The search service API, included in Documentum 5.3 SP1 and later releases, resolves these limitations. The next section covers this extensive API in detail.
The Search Service API
The search service API is rooted at the IDfSearchService interface:
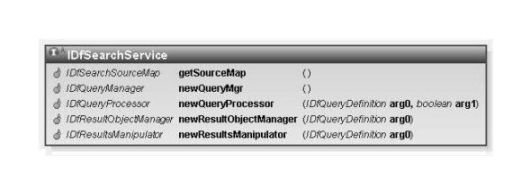
Figure 1:
The IDfSearchService interface.
To obtain an instance of this class, use IDfClient.newSearchService():
IDfSearchService searchService =
new DfClientX().getLocalClient().newSearchService(mgr, repo);
The first parameter of the newSearchService() factory method is an IDfSessionManager that knows connection credentials for all of the repositories you wish to query. The second parameter is a String that specifies the default repository to use for metadata when querying external ECIS sources–you can use null for this parameter in the case that you are only searching Documentum repositories.
Note: ECIS is a Documentum technology that allows arbitrary (non-Documentum) content sources to be adapted and accessed via Documentum search.
Building Queries
Now that we have a search service instance, how do we create a query and then execute it? The way queries are built using the search service API is not through DQL–in fact, the API doesn’t accept DQL at all. Instead, the API requires you to express your query using a query builder (or criteria) API. With this API, you build your query programmatically using the IDfQueryBuilder and related interfaces in the DFC package com.documentum.fc.client.search. Here’s a simple example that demonstrates building a query using IDfQueryBuilder. The query finds all dm_documents whose object_name attribute contains the word “sphygmomanometer”:
IDfQueryManager queryManager = searchService.newQueryMgr();
IDfQueryBuilder query = queryMgr.newQueryBuilder("dm_document");
IDfExpressionSet root = builder.getRootExpressionSet();
root.addSimpleAttrExpression(
"object_name",
IDfValue.DF_STRING,
IDfSimpleAttrExpression.SEARCH_OP_CONTAINS,
true /* isCaseSensitive */,
false /* isRepeated */,
"sphygmomanometer");
There are several methods on the IDfQueryBuilder interface that allow you to specify the details of your query, but in this example we keep things simple and express the query as a single attribute constraint. To understand this API, it helps to see the DQL-equivalent of the built query:
SELECT * FROM dm_document
WHERE object_name LIKE '%sphygmomanometer%'
We should point out that the search service actually generates DQL under the covers for search sources that are Documentum repositories. You can actually see the generated DQL for searches like these by enabling the com.documentum.fc.client.search.impl.generation log in the DFC log4j configuration.
The above query selects all attributes in the query. You can scope the result attributes by specifying them explicitly:
query.addResultAttribute("object_name");
This example restricts the query’s selected attributes to object_name. In this case, the query builder API will automatically add r_object_id to the selected attributes list. If the built query contains a full-text expression, then score will also be added to the selected attribute list.
Attribute constraints are added to an IDfQueryBuilder query through its expression set tree rooted at IDfQueryBuilder.getRootExpressionSet() which returns an IDfExpressionSet instance. With this interface you can express arbitrary, nested logical expressions. We’ll look at a more complicated example, but first let’s introduce a little “adaptor method” to simplify our code–the addSimpleAttrExpression() is just too lengthy:
/**
* Add a case-insensitive 'contains' constraint to the
* provided {@link IDfExpressionSet}. Assume the provided
* attribute name identifies a non-repeating String
* attribute.
*/
void addContains(IDfExpressionSet expressionSet,
String attributeName,
String value)
{
expressionSet.addSimpleAttrExpression(attributeName,
IDfValue.DF_STRING,
IDfSimpleAttrExpression.SEARCH_OP_CONTAINS,
false /* isCaseSensitive */,
false /* isRepeated */,
value);
}
Now we can add simple attribute expressions in a much more concise form:
public IDfQueryBuilder buildQuery(IDfQueryManager queryMgr)
throws DfException
{
// This no-arg factory method defaults to search type
// "dm_sysobject"
IDfQueryBuilder query = queryMgr.newQueryBuilder();
IDfExpressionSet root = query.getRootExpressionSet();
addContains(root, "object_name", "Some File");
addContains(root, "owner_name", "Zarnk");
IDfExpressionSet sub = root.addExpressionSet();
sub.setLogicalOperator(IDfExpressionSet.LOGICAL_OP_OR);
addContains(sub, "subject", "mnemonist");
addContains(sub, "title", "mnemonist");
return query;
}
Note the use of the setLogicalOperator() method. Each expression set has an associated logical operator (one of AND or OR) . The default operator is AND, which is why we don’t have to set the logical operator for the root set. Also note that the OR expression set is added as a member of the AND expression set to form a nested expression. In DQL, the corresponding criteria is:
... FROM dm_sysobject WHERE
(object_name LIKE '%Some File%'
AND owner_name LIKE '%Zarnk%'
AND (subject LIKE '%mnemonist%'
OR title LIKE '%mnemonist%'))
IDfExpressionSet in Detail
IDfExpressionSet is an important part of the query builder API. Here is the full interface:
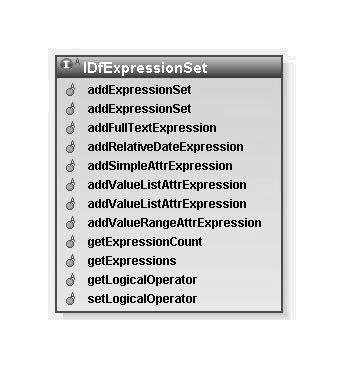
Figure 2:
The IDfExpressionSet interface.
The addFullTextExpression() method has very interesting undocumented behavior, so let’s explore it before we move on. It’s easy to guess the semantics of the following query:
IDfQueryBuilder query = queryManager.newQueryBuilder();
IDfExpressionSet root = query.getRootExpressionSet();
root.addFullTextExpression("Hello");
The DQL equivalent of this query is as you would expect:
... FROM dm_sysobject SEARCH DOCUMENT CONTAINS 'Hello'
But what about the following query?
IDfQueryBuilder query = queryMgr.newQueryBuilder("dm_document");
IDfExpressionSet root = query.getRootExpressionSet();
root.addFullTextExpression("Hello");
root.addFullTextExpression("Goodbye");
IDfExpressionSet sub = root.addExpressionSet();
sub.setLogicalOperator(IDfExpressionSet.LOGICAL_OP_OR);
sub.addFullTextExpression("Whaddup");
addContains(sub, "object_name", "horsefeathers");
This appears to be a valid search for all documents that contain “Hello” and “Goodbye” and either contain “Whaddup” or have an object_name that matches “horsefeathers”. This query cannot be expressed in DQL; in DQL syntax, the SEARCH DOCUMENT CONTAINS clause is separate from the WHERE clause so there is no way to mix full-text search contraints and metadata constraints in a logical expression. It turns out that this query is not supported by the search service API, either. At runtime, the above query will produce in an INVALID_FULLTEXT_EXPRESSION error when executed.
(There is a caveat to this, however. If full-text indexing is disabled in dfc.properties via the dfc.search.fulltext.enabled property, each full-text expression in the above query is automatically converted into a metadata constraint and the query will be succesfully built and executed.)
We’re still not done with the addFullTextExpression() method. Take a look at the following query and try to guess what DQL is generated for it:
IDfQueryBuilder query = queryManager.newQueryBuilder();
IDfExpressionSet root = query.getRootExpressionSet();
root.addFullTextExpression("Bob or Sue");
Here’s a hint. It’s one of the following:
(a) ...FROM dm_sysobject SEARCH DOCUMENT CONTAINS ('Bob or Sue')
(b) ...FROM dm_sysobject SEARCH DOCUMENT CONTAINS ('Bob' or 'Sue')
These are two very different queries that produce drastically different result sets, so the answer is important. Okay, let’s kill the suspense–it’s (b). When the query is prepared for execution, the search service acknowledges the lexical forms of the operators AND and OR when parsing each full-text value and generates DQL with the criteria separated by each operator (also acknowledging parantheses.) In some sense, this is very convenient behavior–when offering a search box to a user in a UI, for example, we won’t have to do this parsing ourselves.
Searching Multiple Repositories
One significant feature of the search service API is its ability to execute a query across multiple repositories. The addSelectedSource() method on the IDfQueryBuilder interface specifies which sources the query should search. As expected, not adding any such selected sources to your query will result in empty results.
As an example, let’s suppose we wish to search two repositories “gargamel” and “punky”. Here’s how you would add these sources to your query:
IDfQueryBuilder query = ...
query.addSelectedSource("gargamel");
query.addSelectedSource("punky");
Recall that the search service we use to execute our search must be created with a session manager that knows the credentials required to access these repositories. Otherwise, the search service will generate errors during query execution.
You can also dynamically query for available sources using IDfSearchService.getSourceMap(). The following example adds all available sources (those visible to the doc broker(s) that are configured in dfc.properties) to a query:
IDfSearchSourceMap sourceMap = searchService.getSourceMap();
IDfEnumeration sources =
sourceMap.getAvailableSources(IDfSearchSource.SRC_TYPE_DOCBASE);
while (sources.hasMoreElements()) {
IDfSearchSource source = (IDfSearchSource) sources.nextElement();
query.addSelectedSource(source.getName());
}
Executing Queries
Now that we know how to build a query, let’s demonstrate how to execute one:
IDfQueryProcessor processor =
service.newQueryProcessor(query, true /* noDuplicates */);
processor.blockingSearch(0);
IDfResultsSet results = processor.getResults();
This example uses the search service to create an IDfQueryProcessor that can execute the search. Then, a blocking search is issued with a timeout of 0 to indicate that the calling thread should not timeout until the search is finished executing. We can also initiate a non-blocking search and monitor the processor for the results as they come in. If you’ve ever developed a WDK application, this is what the WDK search component does in order to dynamically display the status of a search to the user. We’ll touch on asynchronous search in the next section.
Advanced Topics
Asynchronous Search
Aysnchronous searches are invoked via the IDfQueryProcessor.search() method:
final IDfQueryProcessor processor =
service.newQueryProcessor(query, true /* removeDupes */);
processor.addListener(new MyQueryListener());
processor.search();
IDfResultsSet results = processor.getResults();
In this example, we create a listener (implementing IDfQueryListener) that will be notified of search events such as when the search is completed. Then we invoke the query processor’s asynchronous search() method. This method delegates the query processing to separate thread(s) that are responsible for sending the query to the various repositories and collecting and arregating the results. The processor listener we provided will be notified of various events during the results processing.
Because this is an asynchronous search, the thread that invokes the search() method cannot expect the results to be complete right away. The results object in the code above will be populated as the search results are processed. There are couple of ways to determine the status of the search as it is being processed–one is to use a listener object as demonstrated in the above example. Another approach is to use the IDfQueryProcessor.getQueryStatus() method to poll for the status. Note that polling query status in a non-blocking loop is a bad idea–this is the Busy Waiting antipattern.
Results Processing
The previous discussions have demonstrated how to obtain query results when issuing queries through the Search Service API. These results are returned as IDfResultsSet instances. Here we show an example that processes an IDfResultsSet instance by displaying the object_name attribute value for each result entry:
private void showResultObjectNames(IDfResultsSet results) {
for (int i = 0; i < results.size(); ++i) {
IDfResultEntry result = results.getResultAt(i);
String objectName = result.getString("object_name");
System.out.println(objectName);
}
}
The IDfResultEntry interface is extensive; more details can be found in the DFC Javadocs.
Results Sorting
How can we sort results returned through the Search Service API? Use IDfSearchService.newResultsManipulator() to create an instance of IDfResultsManipulator, which you can then use to sort query results:
IDfResultsManipulator manipulator =
searchService.newResultsManipulator(query);
IDfResultsSet sorted =
manipulator.sortBy(results, "object_name", true);
If the results here are from an asynchronous search, then when the sort is issued only, the currently accumulated results are sorted and a new IDfResultSet instance is returned.
Metadata Manager
In some cases it is necessary at runtime to determine metadata about the types and attributes we are searching. Suppose you are building a query and wish to add a constraint on a given attribute. If the attribute isn’t explicitly known to you at development time (for example, it comes from a UI interaction or from user-supplied configuration), then you will need a way to determine certain characteristics of the attribute (e.g., Is it a repeating attribute? What is it’s datatype?) in order to add the constraint. IDfSearchMetadataManager can answer these questions. Using a metadata manager, we can create helpful, generic methods like this one:
/**
* Add an equals constraint to the provided query's root
* expression set using the provided attributeName and value.
*/
public void addEqualsToRootExpression(IDfQueryBuilder query,
String attributeName,
String value)
throws DfException
{
IDfSearchMetadataManager metadata = query.getMetadataMgr();
IDfExpressionSet root = query.getRootExpressionSet();
IDfSearchTypeAssistant type =
metadata.getTypeAssistant(query.getObjectType());
root.addSimpleAttrExpression(attributeName,
type.getAttrDataType(attributeName),
IDfSimpleAttrExpression.SEARCH_OP_EQUAL,
true /* isCaseSensitive */,
type.isAttributeRepeated(attributeName),
value);
}
There are a couple of things to point out here. Each query has its own metadata manager available via IDfQueryBuilder.getMetadataMgr(). Note also that the metadata manager uses the target repositories for the query to answer metadata information. What this means is that whenever you use IDfQueryBuilder.addSelectedSource(), you potentially change the state of the IDfSearchMetadataManager underlying the search.
Note that the metadata manager will only provide metadata for types that have the property is_searchable set to true.
Expression Set Manipulation
In some case you will wish to traverse the entire expression tree rooted at IDfQueryBuilder.getRootExpressionSet(). You can write your own traversal using IDfExpressionSet.getExpressions() which returns an IDfEnumeration of IDfExpression, some of which might be IDfExpressionSet instances that you can recursively traverse. A better way is to use the visitor class DfExpressionVisitor, which is offered to support these kinds of traversals for you. (If you are unfamiliar with the visitor pattern, you will want to review it to make sense of this class.) Here is DfExpressionVisitor:
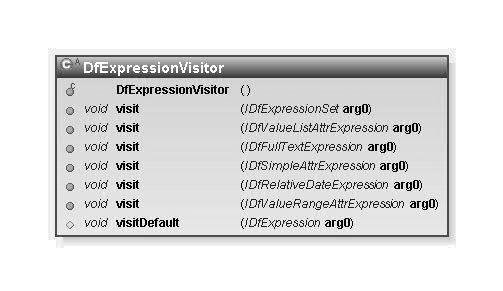
Figure 3:
The DfExpressionVisitor abstract class.
This is an abstract class intended for subclassing. For each type of expression that you would like to process, override the corresponding visit() method. The visitDefault() method is protected and operates as a catch-all case; for each visit() method that you do not override, the abstract base class will delegate the call to visitDefault().
Assuming you have implemented MyDfExpressionVisitor as a subclass of DfExpressionVisitor, here is how you would perform a traversal of the root expression set of a query:
DfExpressionVisitor visitor = new MyDfExpressionVisitor();
query.getRootExpressionSet().acceptVisitor(visitor);
Your visitor can thus manipulate or collect information about each node in the expression tree. If you override the visit(IDfExpressionSet) method, you can change whether the traversal is a preorder or postorder traversal by calling super#visit(IDfExpressionSet) before or after you process the provided IDfExpressionSet node.
An unfortunately missing feature of the IDfExpressionSet API is the ability to clone an expression set. If you need to perform a clone operation on an expression tree, you will need to traverse the tree, determine the type of each expression node, and then map that node to a method on IDfExpressionSet. (There is a copy() method on the IDfQueryBuilder interface that will clone the entire builder and its constituent expression sets, however.)
DQL vs. Search Service
While the search service API offers a broader set of capabilities–such as searching multiple sources and issuing asynchronous searches–DQL is still a more powerful API for issuing searches on single repositories. For example, you cannot create DISTINCT or grouping searches using the search service APIs. For expressive DQL searches like these, you will need to use the simple query API and execute your query for each repository you would like to search.
Debugging Queries
Here are a few very helpful tips for debugging DFC search service behavior.
To see the DQL generated by the query builder APIs, add this to your log4j.properties:
log4j.logger.com.documentum.fc.client.search.impl.generation=DEBUG
Here’s how to print a human-readable history of query processing:
IDfQueryProcessor processor = ...;
System.out.println(processor.getQueryStatus().getHistory());
Finally if you wish to print an XML serialization of an IDfQueryBuilder, try:
IDfQueryManager manager = ...;
manager.saveQueryDefinition(query, System.out);
Conclusion
In this article we have covered many details of the DFC search APIs, including several undocumented features and behaviors. You should now be able to quickly get started using these APIs to build your own DFC search applications. There are certainly more aspects to Documentum and DFC search than we have been able to cover here. Consider exploring some of the other resources and documentation provided at the end of this article to continue to grow your knowledge in these areas.
Notes
Earlier (pre-Documentum 5) versions of DFC had a query builder API that has since been deprecated and removed.
Other Resources
EMC Documentum Search Version 6 Development Guide is an especially helpful document with details on DFC and WDK search development.
EMC Documentum Foundation Classes Version 6 Development Guide provides a thorough review of DFC with brief sections on the DFC search and query APIs.
EMC Documentum Content Server Version 6 DQL Reference Manual is the reference manual for Documentum’s Document Query Language (DQL).
EMC Documentum Content Server Version 6 Full-Text Indexing System Installation and Administration Guide is the installation and deployment guide for Documentum’s Full-Text Indexing System but it also provides a very good overview of full-text indexing and related concepts.


