

The data transformation project at Jack in the Box, to migrate their entire data architecture to AWS Redshift and Tableau, was accomplished using Agile iterations. How did we manage such a large-scale, strategic Data Analytics project using Scrum?

A REALLY Big Project
The scope of the problem at hand was huge: we had three legacy reporting solutions, two different data warehouse environments (Oracle and SQL), 1200 users, 50+ data sources, and hundreds of reports. And we had a mission to retire all of this within a year while moving everything to a modernized AWS Redshift + Tableau environment in the cloud. HOLY HECK, how on earth were we going to meet these objectives with such a massive amount of scope? Under the leadership of a new, visionary CTO, we formed the first agile team within the IT Architecture & Innovation Portfolio at Jack in the Box.
When I joined the Jack team, I was an experienced Agile trainer just coming off another big data project, but I had never tackled a data transformation project of this scale before. Since my fear of letting down my teammates is only equal to my fear of snakes, I was a little nervous about the job in front of me when I touched down at the San Diego airport. Luckily, I had a great team to work with, including a Data Architect and a Data Engineer who were both veterans of the Business Intelligence team.
Creating the Plan....Then Planning Again
In the beginning of any project, estimations are really hard because you’re working with a new team, in a new set of technologies, and most engineers (including myself) tend to be overconfident in how long it will take to figure things out. In this case, the organization was also new to the cloud, so there was a big learning curve for just about every component of the platform and infrastructure setup. At first, we had lofty goals. Boy, were we optimistic and ignorant back then! I hit the ground at the end of January 2018, and our initial decommission target date was just four months later, May 2018, for all platforms.
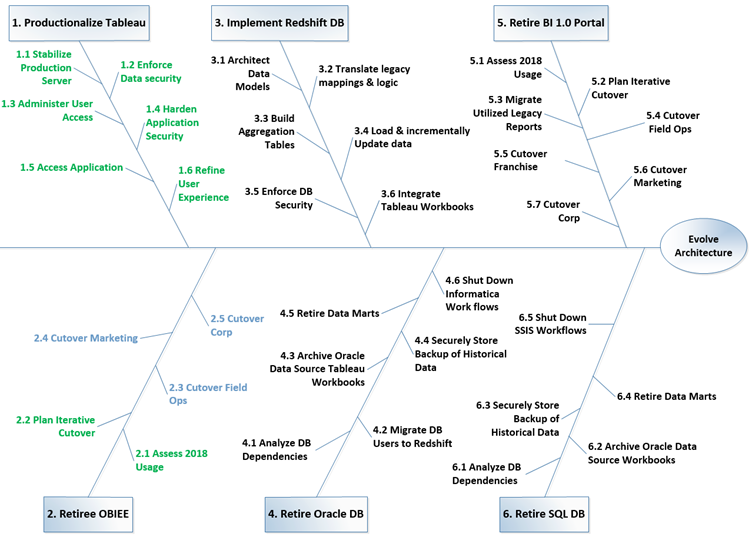
It didn’t take many sprints or much calibration of our velocity to quickly realize that in no way would we hit that objective for all reporting platforms and all legacy data environments. I knew it. The team knew it. For a few weeks we didn’t talk much about it, until finally I presented a draft roadmap to the CTO with the laundry list of things left to accomplish and let her know that MAY AIN’T GONNA HAPPEN. With her inputs, we then tossed the idea of trying to get it all done by a single timeframe, and instead set new goals by environment. We made heavy use of visual models to break down our goals into reasonable feature sets. Feature Trees like Figure 1 below were a big help in allowing us to quickly see how to group features, what was done, and how much was left to go (note that each L1 branch of this tree had a more granular breakdown in its own feature tree as well).
Orchestrating Balanced Sprints
We knew that in order to hit our refined decommission targets, we needed to be laser-focused on our sprint goals and avoid any sort of blockers that would slow us down. And we had to avoid the common pitfall of having too many work-in-progress items active at one time, which ultimately makes it slower to get each individual thing done. We weren’t great at this at first. Because a lot of the team was new to agile, one of the first concepts we had to master was breaking down a feature so that multiple resources could work on it at the same time, without anyone slowing the other down, and while still maintaining a grasp of the big picture and where their parts fit in to the whole.
Our team used Azure DevOps to manage our backlog and sprints (but almost any agile tool will do). One of my favorite features of this platform is a customizable set of object types that allow you to build a hierarchy with as many nodes as you need. We wanted to be sure we could relate everything we were doing all the way back up to the company strategic objectives, so we configured our hierarchy with the following objects:
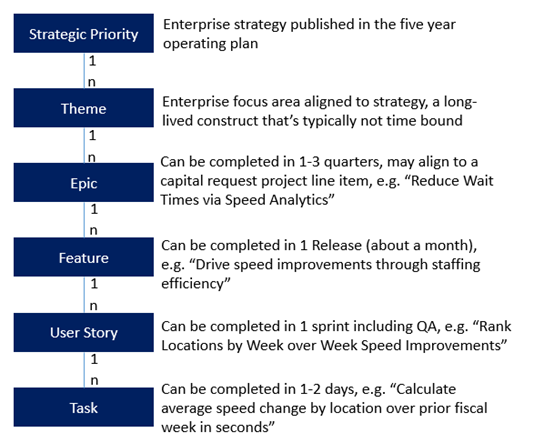
Ensuring our stories all mapped into this requirements hierarchy made it easy to see all of the components required for a feature in one view, made it easier to split out the work across resources, and assign the stories to sprints in a way that would prevent any dependencies.
Learning as We Go
Early on, we made the mistake of including stories for both engineering the data for a source AND publishing a visualization for that same data source in the same sprint. Because at this point, most of the data sources were net new sources that needed to be built from the ground up in the new environment, it would realistically take at least one whole sprint, if not two, to design the right schema, develop the ETL, and validate the data. We learned to carefully track three distinct capacity type buckets in sprint planning, where each capacity type had a different success metric that would contribute to our decommission goal, that we would report in weekly status meetings:
- Product Management capacity, measured by % adopted users on the new platform
- Data capacity, measured by % data sources migrated to Redshift
- Visualization capacity, measured by % of utilized views migrated to Tableau
Once They Go Agile, They Never Go Back!
After the heavy lifting of the migration was complete, we looked to scale down the team and move to “run the business” mode. I helped the Jack team find my replacement, who joined the team and began learning the ins and outs of the wealth of our data and views. When I rolled off, I felt confident that the team was positioned to continue transforming the way Jack users looked at and leveraged data in their processes. As of today, the full-time-employee Data and Analytics team is holding steady and continuing to utilize the agile practices that we developed together. I checked in with them recently to see how things were going.
“We’re still using agile at Jack in the Box and I don’t see that changing anytime soon. Our two-week sprints are a great way to compartmentalize chunks of work as we piece things together for larger feature related rollouts. Organizing work into sprints also enables us to prioritize both our short-term and long-term roadmap, so that we can clearly communicate release dates to our business partners.”
Lessons for the Future
We learned so much, and I continue to think back about the lightbulb moments that hit me throughout the project. Some key lessons learned that can really apply to any Data and Analytics project:
- Sandbag initial estimates for new technologies and account for cloud learning curves (like seriously, probably double what you think at first).
- Don’t commit to a big bang decommission goal, but rather break this down into specific goals by platform, in a clear priority order.
- It’s totally OK for your initial plan to be wrong. This is, after all, agile—an EMPIRICAL process by which we gain knowledge through experience.
- Organize your requirements hierarchy with object definitions everyone can agree to; enforce traceability across every level so that you never lose sight of the big picture.
- Clearly list out all dependencies for a story and call them out in grooming and sprint planning.
- Don’t overcommit, especially with a small team that’s ALSO handling production support cases.
- Don’t get comfortable with moving a story to the next sprint if you can’t get to it. Be clear-cut in your commitments. Limit scope so you can get things from Dev to QA to Production and put a bow on it before the sprint is over. If you do decide to take a risk on uncertain scope, call it out as a stretch goal.
- Curate buckets of capacity in workstreams that can deliver measurable value in parallel (and organize your roadmap and sprints this way). For us, this was product, data, and views; your tracks may be different depending on the context of the project.
- Minimize delays in user story execution through careful sprint orchestration of dependencies (if new data is needed for a view, ensure that’s available at least 1-2 sprints ahead of the dashboard story).
- Define a pattern for your features and leverage it across data sources and visualizations.
- Deeply understand the business decision a stakeholder is trying to make before designing a dashboard for them; we found the use of visualization white papers to be helpful in this regard—not necessarily to create the paper itself, but to create a pattern of thinking processes that facilitates empathy with the user’s data needs.
- Think about adoption from day one and consider it your most important deliverable. Get value into the hands of users from the front-end to vet the experience before investing in full end-to-end development.
- Coach the business on what it means to be agile, how they can contribute to the iterative delivery process, and that every request will require a lifecycle of analysis, design, and delivery.

